MobileNet_v1_v2论文复现,附带与ResNet,VGG网络对比
更新时间:2026-03-26 15:52:35
-

-
taptap官方最新客户端2026
- 类型:生活服务
- 大小:28.8m
- 语言:简体中文
- 评分:
- 查看详情
MobileNet_v1_v2论文复现,附带与ResNet,VGG网络对比
本文详细介绍MobileNet v和 v的创新之处。v用了深度可分离卷积替代标准卷积,结合了深度和点乘运算,显著降低了参数和计算量,并表现出优异的性能。相比之下,v入了残差倒数结构和线性激活函数,显著提高了模型的表现力和泛化能力。通过代码实现并进行测试,两者的速度与精度均得到了大幅提升。在特定任务中,v示了更强的拟合和泛化能力,优于部分传统网络模型。

1.导入必要库
In [1]
import timeimport paddleimport paddle.nn as nnimport paddle.nn.functional as F from paddle.vision.transforms import Compose, Resizefrom PIL import Imageimport matplotlib.pyplot as pltfrom collections import OrderedDictimport copyimport numpy as npimport paddle.fluid as fluidfrom paddle.vision import transforms as transformsfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Normalizefrom time import strftimefrom time import gmtimeimport paddle.vision.models as modelsfrom paddle.vision.models import resnet50from paddle.vision.models import resnet152登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized登录后复制
2.MobileNet v1
2.1必要知识介绍
实际上,VMobileNet是通过将VGG的标准化卷积层替换为深度分离卷积来实现的。
可分离卷积主要有两种类型:空间可分离卷积和深度可分离卷积。
空间可分离卷积
顾名思义,空间可分离意味着将大卷积核分割为多个小卷积核,例如将卷积核拆分为小卷积核。

由于空间可分离卷积不在MobileNet的范围内,就不说了。
深度可分离卷积

深度可分离卷积就是将普通卷积拆分成为一个深度卷积和一个逐点卷积。
标准的卷积操作
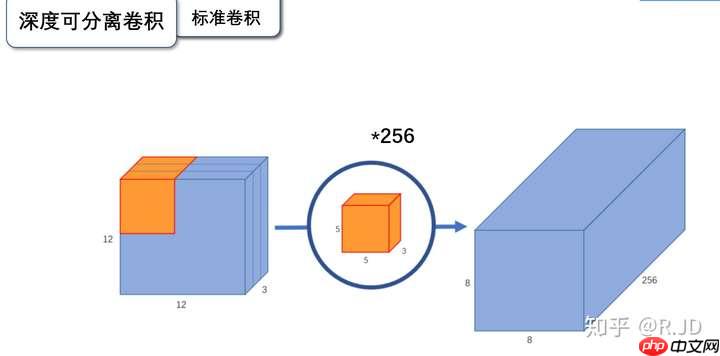
输入一个输入特征图后,经过卷积核卷积得到一个输出特征图。如果此时有特征图,将会得到一个输出特征图。
以上就是标准卷积做干的活。那深度卷积和逐点卷积呢?
深度卷积

与标准卷积网络不同的是,我们将卷积核拆分成单通道形式,在不改变输入特征图像深度的情况下,对每一通道进行卷积操作。结果得到与输入特征图通道数一致的输出特征图。例如:输入一个特征图,经过深度卷积后,将得到输出特征图。输入和输出维度保持不变,这样可以确保获取到足够的有效信息。但是,通道数少可能会限制特征提取能力。因此,在实际应用中,通常需要通过调整参数或增加网络层数来提高模型的表达能力和深度学习算法的效果。
逐点卷积
逐点卷积就是1×1卷积。主要作用就是对特征图进行升维和降维,如下图:
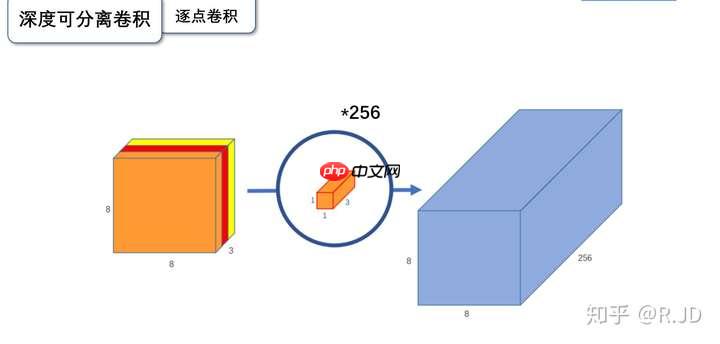
在深度卷积过程中,通过生成一个输出特征图后,我们应用了卷积核进行操作,最终得到的结果与标准的卷积处理一致,形成了一个新特征图。
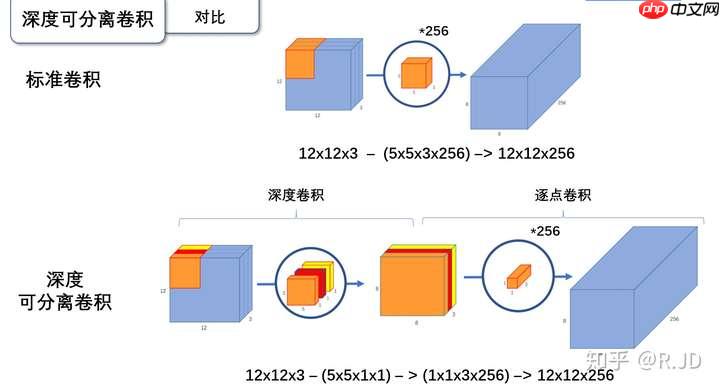
标准卷积与深度可分离卷积的过程对比如下:
应该为12x13x3---(5x5x1x3)--(1x1x3x256)-->12x12x256。
参数量计算
这个问题非常简单,如果你发现一种方法可以利用较少的参数和计算量来达到接近于同等效果的结果,你很可能会采用它。
深度可分离卷积就是这样的一个方法。
深度可分离卷积的参数量由深度卷积和逐点卷积两部分组成:
这一层,MobileNetV1所采用的深度可分离卷积计算量与标准卷积计算量的比值为:
- /924844032 = 0.1189
与我们所计算的九分之一到八分之一一致。
深度可分离卷积层详解
V1卷积层

上图展示了一种标准的卷积层与V独特对比。标准卷积层左边是深度卷积提取特征,然后是一个BN层进行归一化处理,接着是ReLU激活函数,最后完成逐点卷积操作。而右边的V积层则采用了一个深度卷积先于BN和ReLU的方式,这种设计遵循了深度可分离卷积的概念。它通过将标准卷积拆分成深度卷积和逐点卷积两个部分来实现,从而有效地减少了计算量并提升了性能。
等等,我们发现有什么东西混了进来???ReLU6是什么?
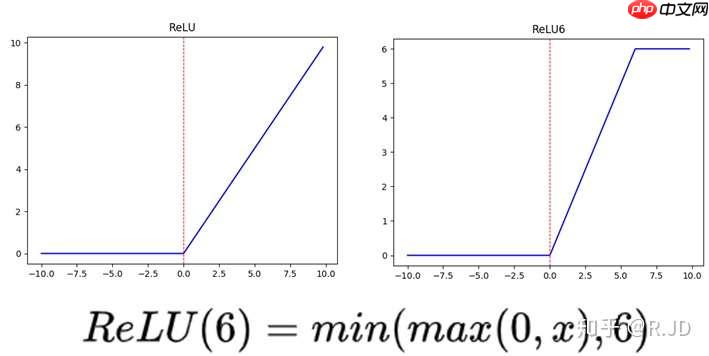
上图左边是普通的ReLU(Rectified Linear Unit),对于输入值大于不进行任何处理。而右边的ReLU有所不同,当输入值超过,其结果直接变为作者指出,相比于普通ReLU,ReLU低精度计算下具有更强的鲁棒性这里的“低精度”并非指float点数格式,而是指定点运算(fixed-point arithmetic)环境。
观察发现,采用深度可分离卷积替代标准卷积后,参数与运算次数分别减至原始值的约四分之一和六分之一左右,然而精度提升幅度仅为。
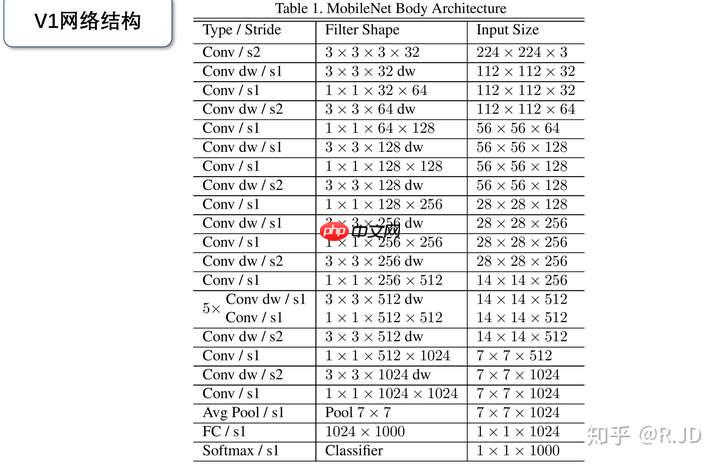
MobileNet的架构示意图如下:首先,通过一个标准卷积通道进行下采样;接着是多个深度可分离卷积堆叠,并在某些部分采用s行进一步缩小;然后应用平均池化层将特征图缩为随后连接全连接层,最后输出softmax分类结果。整个网络包含模块,其中深度卷积层占据多数,达到。

可以观察到,作为轻量化网络的版本V计算量和参数量上均优于GoogleNet,并且分类效果更佳,这是因为它借助了深度可分离卷积技术。相比之下,VGG然其计算量和参数量是V以上,但其分类结果仅高出约百分点。
对了,作者在论文中详细探讨了整个网络的参数与计算量分布情况,如图所示。我们可以明显看出,大部分计算量集中在积上。而参数方面,这也主要集中在积上;除此之外,还有全连接层也占了一部分参数。

torch.nn.Conv2d:对输入的二维图像进行卷积运算
以2 x 3 x 4 x 5 input为例
此时卷积核shape为x x x [out_channels x in_channels x kernel_size x kernel_size]。此时groups参数为表示将in_channels所有通道作为一组,与每一个积核进行卷积操作,总共产生积核的输出,形成不同的特征通道。
首先,让我们对`groups参数`进行一个概要总结:假设输入通道数为`in_channels`, 输出通道数为`out_channels`,分组数量为`groups`。分组卷积是将原本的综合卷积操作分成若干个小组来分别处理,每个小组中的输入通道数为`in_channels / groups`,输出通道数为`out_channels / groups`。最后,所有小组输出的通道数通过concatenate合并,从而得到最终的输出通道数`out_channels`。在进行分组卷积时,需要注意的是,在`in_channels`和`out_channels`上需要确保它们能被`groups`整除,以保证操作的有效性。
2.2代码实现部分
In []
class MobileNet_v1(nn.Layer): def __init__(self): super(MobileNet_v1,self).__init__() #标准卷积 def conv_bn(inp,oup,stride): return nn.Sequential( # stride==1 尺寸不变 # stride==2 尺寸减半 nn.Conv2D(inp,oup,3,stride,1,bias_attr = False), nn.BatchNorm2D(oup), nn.ReLU()) #深度卷积 def conv_dw(inp,oup,stride): return nn.Sequential( # groups!=1时为深度卷积 nn.Conv2D(inp,inp,3,stride,1,groups = inp,bias_attr = False), nn.BatchNorm2D(inp), nn.ReLU(), # 1*1卷积 nn.Conv2D(inp,oup,1,1,0,bias_attr = False), nn.BatchNorm2D(oup), nn.ReLU()) #网络模型声明 self.model = nn.Sequential( #标准卷积 conv_bn(3,32,2), #深度卷积 conv_dw(32,64,1), conv_dw(64,128,2), conv_dw(128,128,1), conv_dw(128,256,2), conv_dw(256,256,1), conv_dw(256,512,2), conv_dw(512,512,1), conv_dw(512,512,1), conv_dw(512,512,1), conv_dw(512,512,1), conv_dw(512,512,1), conv_dw(512,1024,2), conv_dw(1024,1024,1), nn.AvgPool2D(7), ) # 全连接层 self.fc = nn.Linear(1024,10) #网络的前向过程 def forward(self,x): x = self.model(x) x=paddle.reshape(x,[-1, 1024]) x = self.fc(x) return x登录后复制
3.MobileNet v2
3.1必要知识介绍
在MobileNet v结构中,可以观察到其类似于VGG的直筒型设计,而非拥有如ResNet那样的shortcut连接方式。有人反馈指出,MobileNet v络中的深度卷积(DW Convolution)训练效果较为薄弱,导致整体性能提升不明显。为了进一步优化模型表现,我们继续探讨MobileNet v
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。

倒残差结构
刚刚提到MobileNet v亮点在于DW卷积,而MobileNet v展现了Inverted residual block(倒残差结构)。然而,我们发现了其不足之处,并采取了相应的改进措施。
线性激活函数
在卷积操作之后加入激活函数是为了增加特征的非线性特性。最常见的激活函数是ReLu,但根据残差网络中数据处理不等式(DPI)的分析,ReLu会带来显著的信息损失,并且这种损耗无法恢复。信息损耗在通道数量较少时尤为明显。鉴于此,如果我们希望减少信息损失,可以考虑使用线性激活函数代替ReLu。如果能够有效地增加通道数来降低信息损失,那么我们可以选择更多的通道进行处理。

在深度学习的网络架构中,残差连接作为一种常见的技术手段被广泛应用于提升模型训练的速度和准确性。在这个过程中,残差网络采用了一种独特的降维-升维结构,即在前向传播时通过积进行降维处理,在反向传播时使用积进行升维操作。这种设计的主要目的是为了提高网络的效率以及保留模型训练过程中的高维信息。通过ReLU激活函数后,特征图的维度会随着网络层的深度逐渐减小,而从反向传播的角度看,降维处理后的特征图更容易捕捉到高层抽象的特征信息。相反,在倒残差结构中,积升维操作可以更有效地保留和传递这些重要的高维信息,从而进一步增强模型对细节特征的识别能力。这种设计在实际应用中显示出了良好的效果,特别是在图像分类等任务上,能够有效减少过拟合,并且提高了模型训练的速度。
倒残差结构在使用时需注意,非所有倒残差模型都含有短接连接。仅当strides为输入和输出特征矩阵形状相等时才存在这种连接方式(此时只有当输入和输出维度相同时才能进行加法运算),而stride为设置并不一定保证输入和输出通道数相同。
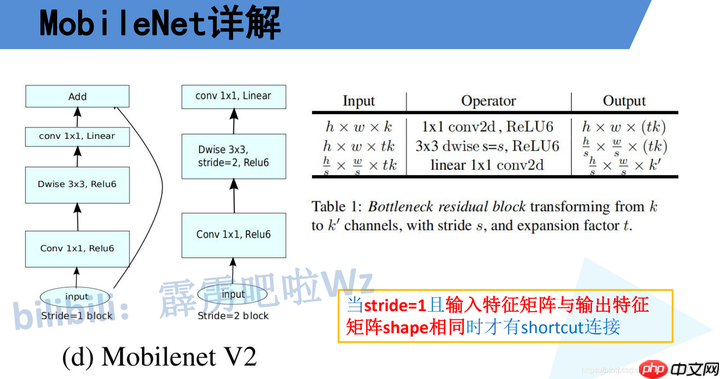
MobileNet v2相关问题
下图是MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n代表倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。 MobileNet V2中的bottleneck为什么先扩张通道数在压缩通道数呢?
因为MobileNet 网络结构的核心就是Depth-wise,此卷积方式可以减少计算量和参数量。而为了引入shortcut结构,若参照Resnet中先压缩特征图的方式,将使输入给Depth-wise的特征图大小太小,接下来可提取的特征信息少,所以在MobileNet V2中采用先扩张后压缩的策略。 MobileNet V2中的bottleneck为什么在1*1卷积之后使用Linear激活函数?
经过积层后的特征图进行了一定程度的压缩后,在应用ReLU激活函数时,其会对所有小于等于零的数值产生截断效果。因此,选择线性(Linear)作为激活函数是合理的策略之一。
MobileNet v1 v2 对比
深度学习领域的MobileNet家族不断壮大,其中最新的成员MobileNet V将Residual Networks与深度可分离卷积巧妙结合。通过分析单通道流形特征,改进残差块设计,特别是在扩展中间层(d)和bottleneck层的线性激活(c)方面,大幅度提升了性能。此外,深度可分离卷积的分离式架构有效降低了模型复杂度,几乎压缩了,实现了高精度与低计算资源的要求之间的平衡。这无疑是对MobileNet系列的一次重大提升!
深度可分离卷积设计卓越,可惜CUDNN支持不足,限制了我们在GPU上优化算法的潜力。然而,对于串行CPU来说,这是一个巨大的优势,特别是在嵌入式设备中,这为MobileNet提供了广阔的市场机遇。
3.2代码实现部分
In []
# 带倒残差的深度可分离卷积class Bottleneck(nn.Layer): def __init__(self, in_channels, out_channels, multiple, stride): super(Bottleneck, self).__init__() self.stride = stride # 1*1卷积升维 self.conv1 = nn.Conv2D( in_channels=in_channels, out_channels=in_channels*multiple, kernel_size=1, stride=1, padding=0 ) self.bn1 = nn.BatchNorm2D(in_channels*multiple) # 深度卷积 self.conv2 = nn.Conv2D( in_channels=in_channels*multiple, out_channels=in_channels*multiple, kernel_size=3, stride=stride, padding=1, groups=in_channels*multiple, ) self.bn2 = nn.BatchNorm2D(in_channels*multiple) # 1*1卷积降维度 self.conv3 = nn.Conv2D( in_channels=in_channels*multiple, out_channels=out_channels, kernel_size=1, stride=1, padding=0 ) self.bn3 = nn.BatchNorm2D(out_channels) self.shortcut = nn.Sequential() if in_channels!=out_channels and stride==1: # 由于stride==1,shape一致,可以做残差连接 即总体上为倒残差结构 self.shortcut = nn.Sequential( # 1*1调整shortcut部分通道数 nn.Conv2D( in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0 ), nn.BatchNorm2D(out_channels), ) def forward(self, x): out = F.relu6(self.bn1(self.conv1(x))) out = F.relu6(self.bn2(self.conv2(out))) # 最后一层采用线性激活函数 out = self.bn3(self.conv3(out)) # 如果stride==1,故shape一致,可以做残差连接 即总体上为倒残差结构 if self.stride==1: out = out + self.shortcut(x) return outclass MobileNet_v2(nn.Layer): parameters = [ (1,16,1,1), (6,24,2,2), (6,32,3,2), (6,64,4,2), (6,96,3,1), (6,160,3,2), (6,320,1,1)] def __init__(self,num_classes=10): super(MobileNet_v2,self).__init__() self.conv1 = nn.Conv2D( in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1 ) self.bn1 = nn.BatchNorm2D(32) self.bottleneck = self.Make_Bottleneck() self.conv2 = nn.Conv2D( in_channels=320, out_channels=1280, kernel_size=1, stride=1, padding=0 ) self.bn2 = nn.BatchNorm2D(1280) self.linear = nn.Linear(1280,num_classes) def Make_Bottleneck(self): layers = [] in_channels = 32 for parameter in self.parameters: strides = [parameter[3]] + [1]*(parameter[2]-1) for stride in strides: layer = Bottleneck(in_channels, parameter[1], parameter[0], stride) layers.append(layer) in_channels = parameter[1] return nn.Sequential(*layers) def forward(self, x): out = F.relu6(self.bn1(self.conv1(x))) out = self.bottleneck(out) out = F.relu6(self.bn2(self.conv2(out))) out = F.avg_pool2d(out, 4) out = F.avg_pool2d(out, 3) out=paddle.reshape(out,[out.shape[0], -1]) out = self.linear(out) return out登录后复制 In []
#速度评估def speed(model,name): t0 = time.time() input = paddle.rand([1,3,224,224]) t1 = time.time() model(input) t2 = time.time() model(input) t3 = time.time() print('%10s : %fs'%(name,t3 - t2))登录后复制
4.速度测评
resnet50
resnet152
vgg16
vgg19
mobilenet_v1
mobilenet_v2 In []
resnet50 = models.resnet50() resnet152 = models.resnet152() vgg16 = models.vgg16() vgg19 = models.vgg19() mobilenet_v1 = MobileNet_v1() mobilenet_v2 = MobileNet_v2() speed(resnet50,'resnet50') speed(resnet152,'resnet152') speed(vgg16,'vgg16') speed(vgg19,'vgg19') speed(mobilenet_v1,'mobilenet_v1') speed(mobilenet_v2,'mobilenet_v2')登录后复制
5.结果展示与分析
resnet50 : 0.019720s
resnet152 : 0.058257s
vgg16 : 0.004025s
vgg19 : 0.004707s
mobilenet_v1 : 0.008120s
mobilenet_v2 : 0.020288s
可能是由于参数数量的差别,造成了速度上的微小变化。还受到硬件配置的影响,在不同的地方运行时,无论是使用MobileNet_V是MobileNet_V相比VGG网络都要更快。
6.精度分析(以分类任务为例
使用Cifar10数据集测试MobileNet_v1,MobileNet_v2的精度 In [4]
transform_train = Compose([ transforms.Resize([224, 224]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]) transform_test = Compose([ transforms.Resize([224, 224]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]) LR = 0.001EPOCHES = 3BATCHSIZE = 100trainset=Cifar10(data_file=None, mode='train', transform=transform_train, download=True) testset=Cifar10(data_file=None, mode='test', transform=transform_test, download=True) trainloader = paddle.io.DataLoader(trainset, batch_size=BATCHSIZE, shuffle=True, num_workers=2) testloader = paddle.io.DataLoader(testset, batch_size=BATCHSIZE, shuffle=False, num_workers=2)登录后复制
6.1训练mobilenet_v1
In []
mobilenet_v1 = MobileNet_v1() optimizer = paddle.optimizer.Adam(learning_rate=LR,parameters=mobilenet_v1.parameters()) loss_function = nn.CrossEntropyLoss()for ep in range(EPOCHES): train_correct = 0 train_sum=0 epoch_used_time=0 epoch_ave_time=0 time_start=time.time() for i,(img, label) in enumerate(trainloader): optimizer.clear_grad() mobilenet_v1.train() out = mobilenet_v1(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() train_correct += (pre_num == label.cpu().numpy()).sum() train_sum+=BATCHSIZE loss = loss_function(out, label) loss.backward() optimizer.step() epoch_used_time+=(time.time()-time_start) time_start=time.time() used_t=strftime("%H:%M:%S", gmtime(epoch_used_time)) total_t=strftime("%H:%M:%S", gmtime((epoch_used_time/(i+1))*len(trainloader))) print(f"\rEpoch:{str(ep)} Iter {train_sum}/{len(trainloader)*BATCHSIZE} Train ACC: {(train_correct/train_sum):.5}\ Used_Time:{used_t} / Total_Time:{total_t}",end="") print('') vote_correct = 0 test_sum=0 for img, label in testloader: mobilenet_v1.eval() out = mobilenet_v1(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() vote_correct += (pre_num == label.cpu().numpy()).sum() test_sum+=BATCHSIZE print(f"\rEpoch:{str(ep)} Iter {test_sum}/{len(testloader)*BATCHSIZE} Test ACC: {(vote_correct/test_sum):.5}",end="") print('')登录后复制
mobilenet_v1 3 Epoch 效果
Epoch:0 Iter 50000/50000 Train ACC: 0.47304 Used_Time:00:01:37 / Total_Time:00:01:37
Epoch:0 Iter 10000/10000 Test ACC: 0.5915
Epoch:1 Iter 50000/50000 Train ACC: 0.65172 Used_Time:00:01:39 / Total_Time:00:01:39
Epoch:1 Iter 10000/10000 Test ACC: 0.6733
Epoch:2 Iter 50000/50000 Train ACC: 0.73912 Used_Time:00:01:40 / Total_Time:00:01:40
Epoch:2 Iter 10000/10000 Test ACC: 0.7497
6.2训练mobilenet_v2
In []
from paddle.vision.models import mobilenet_v2 mobilenet_v2 = mobilenet_v2(pretrained=False) optimizer_v2 = paddle.optimizer.Adam(learning_rate=LR,parameters=mobilenet_v2.parameters()) loss_function = nn.CrossEntropyLoss()for ep in range(EPOCHES): train_correct = 0 train_sum=0 epoch_used_time=0 epoch_ave_time=0 time_start=time.time() for i,(img, label) in enumerate(trainloader): optimizer_v2.clear_grad() mobilenet_v2.train() out = mobilenet_v2(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() train_correct += (pre_num == label.cpu().numpy()).sum() train_sum+=BATCHSIZE loss = loss_function(out, label) loss.backward() optimizer_v2.step() epoch_used_time+=(time.time()-time_start) time_start=time.time() used_t=strftime("%H:%M:%S", gmtime(epoch_used_time)) total_t=strftime("%H:%M:%S", gmtime((epoch_used_time/(i+1))*len(trainloader))) print(f"\rEpoch:{str(ep)} Iter {train_sum}/{len(trainloader)*BATCHSIZE} Train ACC: {(train_correct/train_sum):.5}\ Used_Time:{used_t} / Total_Time:{total_t}",end="") print('') vote_correct = 0 test_sum=0 for img, label in testloader: mobilenet_v2.eval() out = mobilenet_v2(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() vote_correct += (pre_num == label.cpu().numpy()).sum() test_sum+=BATCHSIZE print(f"\rEpoch:{str(ep)} Iter {test_sum}/{len(testloader)*BATCHSIZE} Test ACC: {(vote_correct/test_sum):.5}",end="") print('')登录后复制
mobilenet_v2 3 Epoch 效果
Epoch:0 Iter 50000/50000 Train ACC: 0.50066 Used_Time:00:01:43 / Total_Time:00:01:43
Epoch:0 Iter 10000/10000 Test ACC: 0.5784
Epoch:1 Iter 50000/50000 Train ACC: 0.6868 Used_Time:00:01:43 / Total_Time:00:01:433
Epoch:1 Iter 10000/10000 Test ACC: 0.7133
Epoch:2 Iter 50000/50000 Train ACC: 0.76648 Used_Time:00:01:43 / Total_Time:00:01:43
Epoch:2 Iter 10000/10000 Test ACC: 0.7486
6.3训练其他网络以对比效果
In [5]
net = models.resnet50(pretrained=False) optimizer = paddle.optimizer.Adam(learning_rate=LR,parameters=net.parameters()) loss_function = nn.CrossEntropyLoss()for ep in range(EPOCHES): train_correct = 0 train_sum=0 epoch_used_time=0 epoch_ave_time=0 time_start=time.time() for i,(img, label) in enumerate(trainloader): optimizer.clear_grad() net.train() out = net(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() train_correct += (pre_num == label.cpu().numpy()).sum() train_sum+=BATCHSIZE loss = loss_function(out, label) loss.backward() optimizer.step() epoch_used_time+=(time.time()-time_start) time_start=time.time() used_t=strftime("%H:%M:%S", gmtime(epoch_used_time)) total_t=strftime("%H:%M:%S", gmtime((epoch_used_time/(i+1))*len(trainloader))) print(f"\rEpoch:{str(ep)} Iter {train_sum}/{len(trainloader)*BATCHSIZE} Train ACC: {(train_correct/train_sum):.5}\ Used_Time:{used_t} / Total_Time:{total_t}",end="") print(' ') print(' ') vote_correct = 0 test_sum=0 for img, label in testloader: net.eval() out = net(img) prediction = paddle.argmax(out, 1) pre_num = prediction.cpu().numpy() vote_correct += (pre_num == label.cpu().numpy()).sum() test_sum+=BATCHSIZE print(f"\rEpoch:{str(ep)} Iter {test_sum}/{len(testloader)*BATCHSIZE} Test ACC: {(vote_correct/test_sum):.5}",end="") print(' ') print(' ')登录后复制
可见mobilenet_v2与mobilenet_v1训练所用时间差不多,但是mobilenet_v2的拟合能力更强,且最终的泛化表现也较好 In []
<br/>登录后复制
以上就是MobileNet_v1_v2论文复现,附带与ResNet,VGG网络对比的详细内容,更多请关注其它相关文章!






















