【论文复现】 MnasNet复现以及一些感想
更新时间:2026-03-26 15:01:12
-

-
taptap官方最新客户端2026
- 类型:生活服务
- 大小:28.8m
- 语言:简体中文
- 评分:
- 查看详情
【论文复现】 MnasNet复现以及一些感想
本文围绕MnasNet进行深入复现,这一网络是由谷歌提出的一种轻量化深度学习模型。它通过自动搜索最佳的精度与延迟平衡点,并在真实手机环境中测量延迟来评估其性能。为了实现这一目标,我们基于PyTorch开发并移植到Paddle中。调整了因硬件限制需要修改的部分参数,并采用预热策略加速训练过程。在训练过程中遇到了一些精度提升的问题,并提出了相应的解决方案。最后,分享了复现成果和心得体会。

【论文复现】 MnasNet复现以及一些感想
简介
概述
MnasNet( mobile neural architecture search),是谷歌提出的一个轻量化网络。
卷积神经网络一直对移动端设备构成挑战,因为它们需要小且高效的模型来适应移动计算的需求。尽管CNN模型经过了各种改进以优化移动端性能,但手动平衡精度和延迟之间的关系仍然困难。自动移动神经架构搜索(MNAS)方法则巧妙地将模型的延迟纳入其主要目标,旨在找到既能保持高精度又能减少延迟的模型。
与之前的方法预估延迟不同的是,他们直接采用真实环境中手机上的模型预测延时。在此之前,方法通常是采用不精确的模式(如:FLOPS)。为了在灵活性和搜索空间大小之间取得适当的平衡,作者提出了一种新的分解层次搜索空间,它鼓励整个网络中的层多样性。实验结果表明,他们的方法始终优于当时最先进的移动端的CNN跨多个视觉任务的模型。在ImageNet分类任务中取得了的精确度,并且在手机端的延时为s,速度是mobileNetV,同时精确度比其高。
Mnasnet是介于MobilenetVMobilenetV间的网络,通过强化学习优化得到的。其结构设计独特且高效。
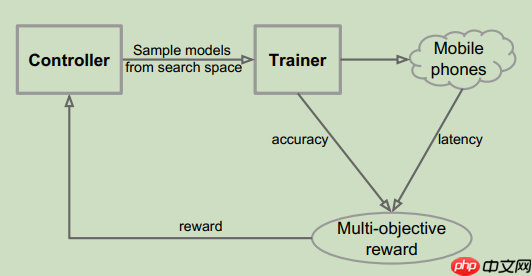
实验方法:
本文展示了在ImageNet数据集上直接搜索CNN模型的方法,而不仅仅是基于较小任务如CIFAR-作者提出了一种新颖的策略,从训练集中随机选择图像作为固定验证集,并利用了与NASNet相同的RNN控制器来提高效率。与之前的方法相比,这种方法节省了数天的时间并显著提高了搜索空间中的模型精度。
在TPUv备上,每个模型搜索需要约的时间。在此过程中,采用Pixel 机的单线程大CPU内核来测量每个采样模型的真实延迟。总计评估了个模型,但仅存下性能最佳的被传输至完整的ImageNet。此外,只有一款模型能够迁移到COCO数据集上使用。
模型结构

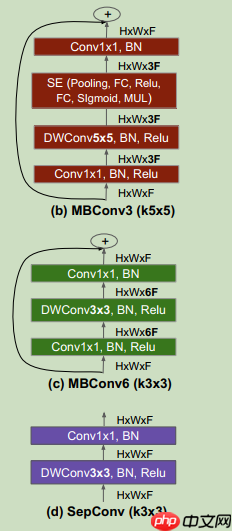
与传统模型有所区别的是,本模型采用了包括内的多种卷积策略。图示中,左图展示了整个架构的设计框架,而右图则详细说明了其组成部分及其功能定位。
实现
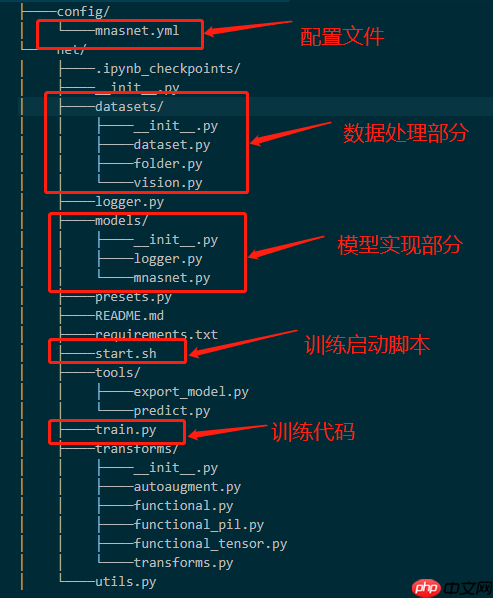
mnasnet的实现基于pytorch,尽管如此,由于paddlepaddle和pytorch在接口实现上的相似之处,使得复现过程速度显著提升。然而,这也带来了新的挑战,需要逐一解决。具体来说,在关键点上,我们主要关注的是Paddle版本模型的实现,并对paddlepaddle的具体细节进行了详细说明。
代码的具体实现在路径:work/PP-Mnasnet/net/models/mnasnet.py下面,大家有问题的可以细看。代码结构如下
参数及方法设置
在进行模型优化时,虽然论文提供了优化器和学习率的学习方法,但实际应用过程中因为不同的硬件环境,通常需要对这些参数进行调整以获得最佳性能。
先列举论文中用到的一些方法及参数:
input_size: 224 X 224 bach_size: 4K warm_up: True / 5 epoch lr_scheduler: RMSProp lr:0.256 dropout:0.2 momentum:0.9

单看Batch_size大小为,并非所有硬件能轻松胜任。据称,该模型启动时投入了美元的预算。因此,应根据实际需求调整Batch_size设置。
对于基于梯度下降的学习率(LR),我们同样需要进行适当的调整,不宜设置为论文中的固定值如果初始学习率过大,在经过数个训练轮次后,模型的准确性和其他关键性能指标通常不会显著改善,如如下情形:- 在几十个epoch后, - 准确率(Acc)和其他相关参数几乎没有明显的提升。 这种情况下,我们可能需要减少学习率或尝试调整其优化策略。通过调整学习率,我们可以更有效地训练模型并提高预测的准确性。
top1: 0.00090, top5: 0.00473, lr: 0.20480, loss: 7.93936, avg_reader_cost: 0.04303 sec, avg_batch_cost: 0.10214 sec, avg_samples: 64.0, avg_ips: 626.62028 top1: 0.00105, top5: 0.00488, lr: 0.20480, loss: 7.69394, avg_reader_cost: 0.04656 sec, avg_batch_cost: 0.10620 sec, avg_samples: 64.0, avg_ips: 602.63657 top1: 0.00094, top5: 0.00434, lr: 0.20480, loss: 8.00038, avg_reader_cost: 0.04546 sec, avg_batch_cost: 0.10643 sec, avg_samples: 64.0, avg_ips: 601.34891 top1: 0.00086, top5: 0.00512, lr: 0.20480, loss: 7.47677, avg_reader_cost: 0.04140 sec, avg_batch_cost: 0.10397 sec, avg_samples: 64.0, avg_ips: 615.57468 top1: 0.00125, top5: 0.00508, lr: 0.20480, loss: 7.45593, avg_reader_cost: 0.04609 sec, avg_batch_cost: 0.10522 sec, avg_samples: 64.0, avg_ips: 608.27140 top1: 0.00086, top5: 0.00527, lr: 0.20480, loss: 7.76873, avg_reader_cost: 0.04692 sec, avg_batch_cost: 0.10712 sec, avg_samples: 64.0, avg_ips: 597.46578 top1: 0.00078, top5: 0.00453, lr: 0.20480, loss: 7.49132, avg_reader_cost: 0.04431 sec, avg_batch_cost: 0.10443 sec, avg_samples: 64.0, avg_ips: 612.87012 top1: 0.00074, top5: 0.00492, lr: 0.20480, loss: 7.57973, avg_reader_cost: 0.05430 sec, avg_batch_cost: 0.11359 sec, avg_samples: 64.0, avg_ips: 563.42090 top1: 0.00086, top5: 0.00508, lr: 0.20480, loss: 7.92624, avg_reader_cost: 0.04599 sec, avg_batch_cost: 0.10737 sec, avg_samples: 64.0, avg_ips: 596.08218 top1: 0.00102, top5: 0.00465, lr: 0.20480, loss: 8.07673, avg_reader_cost: 0.05052 sec, avg_batch_cost: 0.10950 sec, avg_samples: 64.0, avg_ips: 584.49763登录后复制
warmup是一项有效的提高分数的方法,它能加速模型的适应过程。借助ImageNet数据集(包含类别),我们需要一个约B的数据量进行完整训练。在AISSTUDIO中,这也可能需要相当长的时间。
经过精心规划的方法策略后,初始的训练集首先利用官方提供的一般B的数据集进行了训练。然而,在实际操作中,仅仅一天的时间内模型在测试结果上就有所提升。随即尝试了新的训练方法:先在miniImageNet上的少量数据进行预训练,接下来仅需时左右即可达到右的准确率。这种新颖的策略显著提高了训练效率和质量,远超直接使用所有数据集进行训练的结果。
训练代码已在work/PP-Mnasnet/net/train.py中实现。经训练,模型ACC精度可达约
[2021/12/30 13:07:21] root INFO: [Epoch 91, iter: 16400] top1: 0.63598, top5: 0.83176, lr: 0.00120, loss: 1.79083, avg_reader_cost: 0.05147 sec, avg_batch_cost: 0.10281 sec, avg_samples: 64.0, avg_ips: 622.48323 images/sec.[2021/12/30 13:08:16] root INFO: [Epoch 91, iter: 16800] top1: 0.63836, top5: 0.83211, lr: 0.00120, loss: 1.45224, avg_reader_cost: 0.04990 sec, avg_batch_cost: 0.10145 sec, avg_samples: 64.0, avg_ips: 630.85575 images/sec.[2021/12/30 13:09:10] root INFO: [Epoch 91, iter: 17200] top1: 0.63187, top5: 0.83004, lr: 0.00120, loss: 1.95962, avg_reader_cost: 0.04719 sec, avg_batch_cost: 0.09977 sec, avg_samples: 64.0, avg_ips: 641.49160 images/sec.[2021/12/30 13:10:05] root INFO: [Epoch 91, iter: 17600] top1: 0.63000, top5: 0.83313, lr: 0.00120, loss: 1.98715, avg_reader_cost: 0.05027 sec, avg_batch_cost: 0.10245 sec, avg_samples: 64.0, avg_ips: 624.67859 images/sec.[2021/12/30 13:10:59] root INFO: [Epoch 91, iter: 18000] top1: 0.62883, top5: 0.82902, lr: 0.00120, loss: 1.93626, avg_reader_cost: 0.04727 sec, avg_batch_cost: 0.10032 sec, avg_samples: 64.0, avg_ips: 637.96714 images/sec.[2021/12/30 13:11:53] root INFO: [Epoch 91, iter: 18400] top1: 0.62855, top5: 0.82527, lr: 0.00120, loss: 1.35887, avg_reader_cost: 0.04998 sec, avg_batch_cost: 0.10153 sec, avg_samples: 64.0, avg_ips: 630.35848 images/sec.[2021/12/30 13:12:49] root INFO: [Epoch 91, iter: 18800] top1: 0.62773, top5: 0.82719, lr: 0.00120, loss: 1.83990, avg_reader_cost: 0.05086 sec, avg_batch_cost: 0.10312 sec, avg_samples: 64.0, avg_ips: 620.65365 images/sec.[2021/12/30 13:13:43] root INFO: [Epoch 91, iter: 19200] top1: 0.63160, top5: 0.82840, lr: 0.00120, loss: 1.59238, avg_reader_cost: 0.04715 sec, avg_batch_cost: 0.10000 sec, avg_samples: 64.0, avg_ips: 639.99664 images/sec.[2021/12/30 13:14:38] root INFO: [Epoch 91, iter: 19600] top1: 0.63152, top5: 0.83004, lr: 0.00120, loss: 1.68316, avg_reader_cost: 0.05057 sec, avg_batch_cost: 0.10349 sec, avg_samples: 64.0, avg_ips: 618.40716 images/sec.[2021/12/30 13:15:31] root INFO: [Epoch 91, iter: 20000] top1: 0.63129, top5: 0.82945, lr: 0.00120, loss: 1.62996, avg_reader_cost: 0.04641 sec, avg_batch_cost: 0.09755 sec, avg_samples: 64.0, avg_ips: 656.05389 images/sec.[2021/12/30 13:15:34] root INFO: The best model is in epoch [91] and the acc1 is [0.6335090398788452]登录后复制
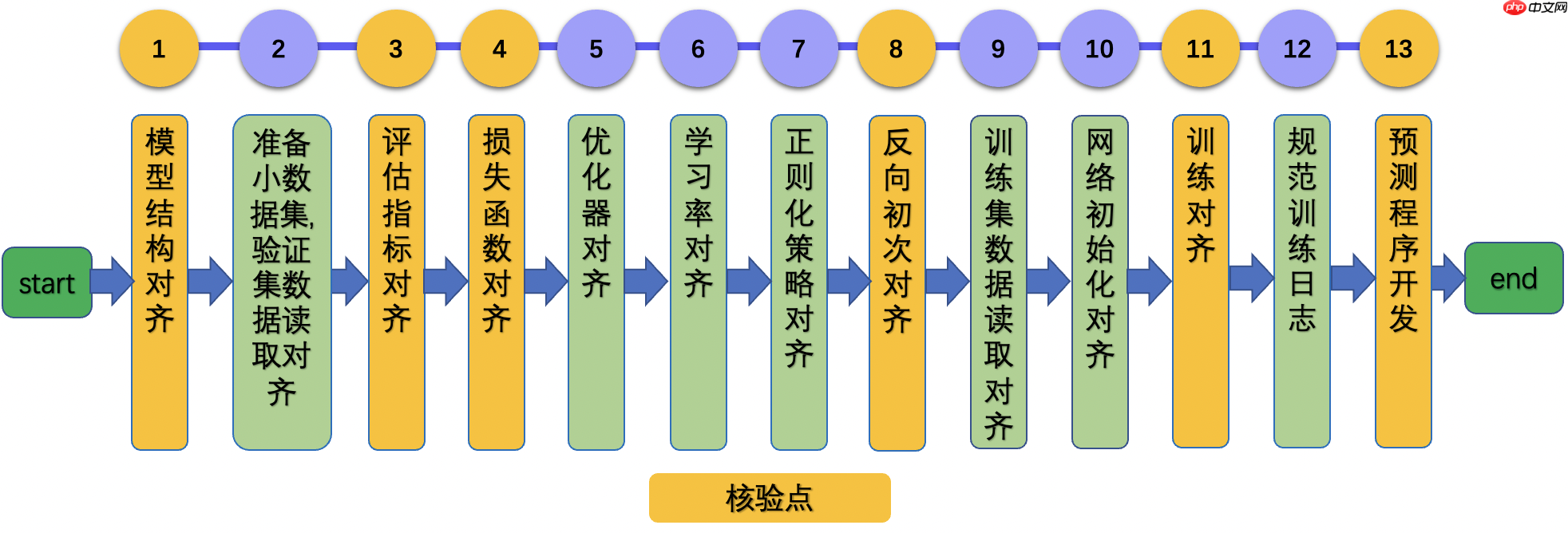
论文复现流程:
官方在论文复现方面有个很好的流程,具体可参考
在复现中如果出现精度等其他问题,可以参考官方推荐的流程进行核对对齐
出现的问题(目前已初步知晓):
在达到,ACC没有继续提升,但通过复现并加入ReLU激活层(如工作目录下的网络可分离卷积模型,在代码中work/PP-Mnasnet/net/models/mnasnet.py第添加)后,acc可以显著提高至接近
参考了Paddle模型库中的可分离卷积实现,最后一步通常包含激活函数(如ReLU或HARD_SWISH),以优化网络性能,特别是对于轻量级的神经网络来说更为有效。关于ReLU和HARD_SWISH这两种常用的激活函数,其背后的具体差异及其原因目前并不完全清楚,需要有经验的大佬在评论区解惑。
这次复现显著受益于深入理解和模块化编程的实践。重点关注代码细节并增强对源码的解读及自我批判思维非常重要。
以上就是【论文复现】 MnasNet复现以及一些感想的详细内容,更多请关注其它相关文章!






















