【论文复现】基于 PaddlePaddle 实现 GreedyHash
更新时间:2026-03-27 13:30:08
-

-
taptap官方最新客户端2026
- 类型:生活服务
- 大小:28.8m
- 语言:简体中文
- 评分:
- 查看详情
【论文复现】基于 PaddlePaddle 实现 GreedyHash
基于PaddlePaddle的GreedyHash算法在CIFAR-据集上实现,精度达到最高,优于原论文与PyTorch重跑结果。提供完整代码和权重。

【论文复现-图像分类检索】基于 PaddlePaddle 实现 GreedyHash(NeurIPS2018)
原论文:Greedy Hash: Towards Fast Optimization for Accurate Hash Coding in CNN.
官方原版代码(基于PyTorch)GreedyHash.
第三方参考代码(基于PyTorch)DeepHash-pytorch.
本项目GitHub repopaddle_greedyhash
1. 简介
Greedy Hash 目标解决图像检索领域中 Deep Hashing 领域 NP 优化难题。作者通过每次迭代更新网络参数的方式,在前向传播阶段确保离散解的限制条件,严格使用 sign 函数。反向传播过程中梯度完整地传递给前一层,从而避免了梯度弥散现象。算法伪代码如下:
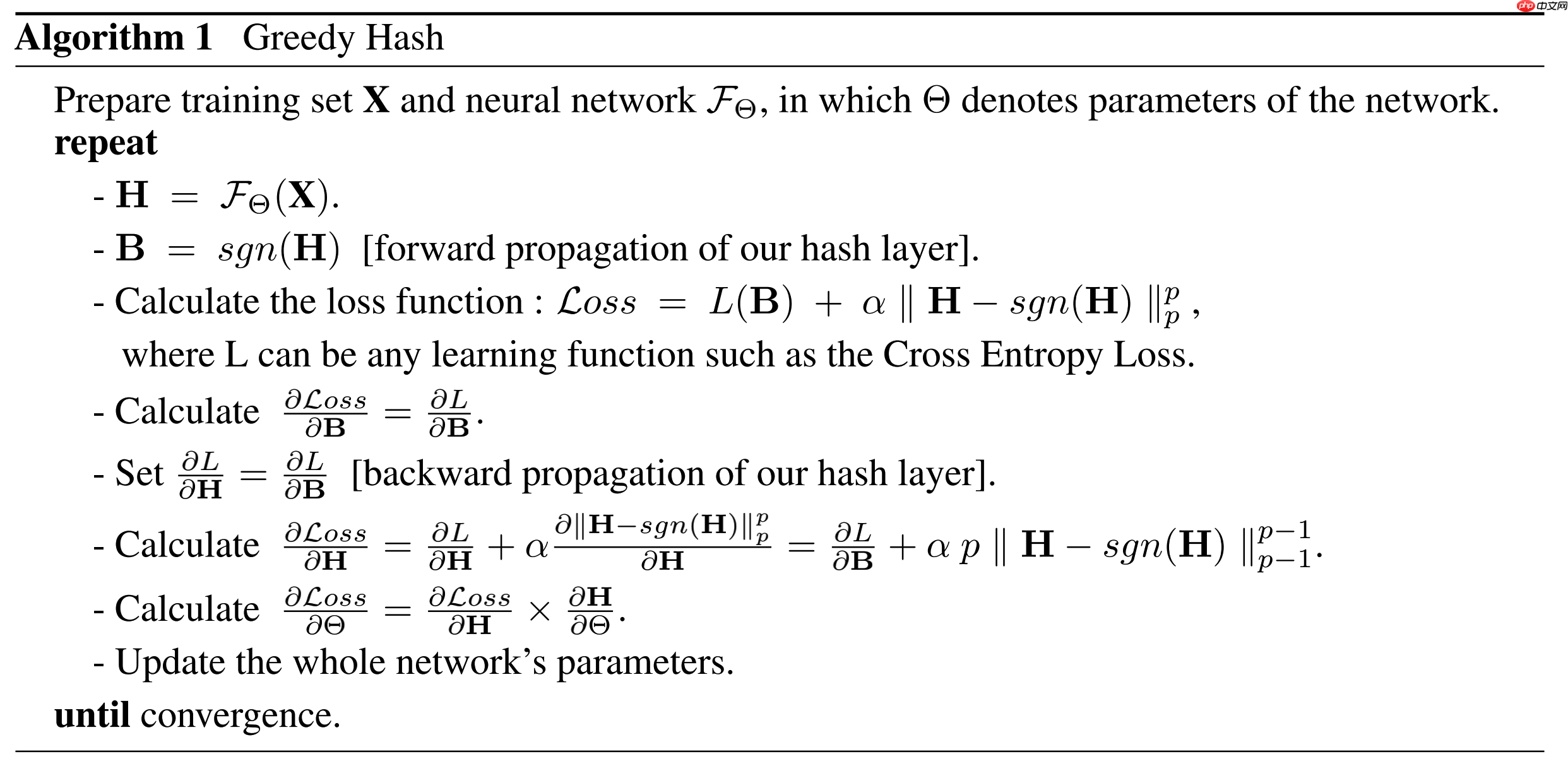
GreedyHash 算法伪代码
2. 数据集和复现精度
数据集:cifar-1(即CIFAR-10 (I))
CIFAR-10 数据集共10类,由 60,000 个 32×32 的彩色图像组成。
在CIFAR-(I)的数据集中,选择图像(每类),作为查询集;其余的图像则作为数据库中的内容。为了进行训练,从数据库中随机抽取了图像(每类),构成训练集。整个数据集处理代码位于utils/datasets.py文件中。
复现精度
需要特别注意的是,在重新运行使用PyTorch版本的代码时,发现原论文中的GreedyHash/cifarpy由于使用较老版本的PyTorch编写的CIFAR-据集处理部分无法正常工作。因此,我选择将DeepHash-pytorch项目中关于CIFAR-数据集处理代码复制粘贴过来进行运行,并以此为模板进行重跑,最终成功实现了PyTorch版本的代码运行。为了确保准确性和可复现性,我已经将修改后的PyTorch版本代码以及训练日志全部保存在了pytorch_greedyhash/main.py和pytorch_greedyhash/logs目录中。由于初期未设置随机数种子,可能会导致部分结果的微小偏差,但总体来说误差应该是在可以接受的范围内,并且问题不严重。
本项目(基于PaddlePaddle)依次运行了的结果列表中,在输出文件夹下已存放训练得到的模型参数及日志信息。尽管我们设置了随机数种子以实现可重复性,但多次反复试验仍显示结果之间存在波动,例如有达到了精度的我们将对应于此情况的日志和权重存放在output/bitalone路径中,这进一步证实了算法的随机性质依然未被完全消除。
3. 准备环境
本人环境配置:
Python: 3.7.11
PaddlePaddle: 2.2.2
硬件:NVIDIA 2080Ti * 1
p.s. 因为数据集很小,所以放单卡机器上跑了,多卡的代码可能后续补上
4. 快速开始
step1: 下载本项目及训练权重
本项目在AI Studio上,您可以选择fork下来直接运行。首先,cd到paddle_greedyhash项目文件夹下: In []
cd paddle_greedyhash登录后复制
/home/aistudio/paddle_greedyhash登录后复制
或者,您也可以从GitHub上git本repo在本地运行:
git clone https://github.com/hatimwen/paddle_greedyhash.gitcd paddle_greedyhash登录后复制
权重部分:
因权重总计达B,已存于百度网盘。如需按项目结构整理各权重文件,请自行下载;若仅想测试性能可选择特定bit位数进行加载。
下载链接:BaiduNetdisk, 提取码: tl1i 。
注意:在AI Studio上,已上传了 bit_48.pdparams 权重文件在 output 路径下,方便体验。
step2: 修改参数
请根据实际情况,修改main.py中的 arguments 配置内容(如:batch_size等)。
step3: 验证模型
需要提前下载并排列好BaiduNetdisk中的各个预训练模型。
注意:在AI Studio上,由于已预先上传bit_48.pdparams 权重文件,因此可以直接运行: In []
# 验证模型! python eval.py --batch-size 32 --bit 48登录后复制
W0427 21:33:47.931723 449 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0427 21:33:47.935976 449 device_context.cc:465] device: 0, cuDNN Version: 7.6. Loading AlexNet state from path: /home/aistudio/paddle_greedyhash/models/AlexNet_pretrained.pdparams 0427 09:33:53 PM Namespace(batch_size=32, bit=48, crop_size=224, dataset='cifar10-1', log_path='logs/', model='GreedyHash', n_class=10, pretrained=None, seed=2000, topK=-1) 0427 09:33:53 PM ----- Pretrained: Load model state from output/bit_48.pdparams --- Calculating Acc : 100%|| 32/32 [00:02<00:00, 13.36it/s] --- Compressing(train) : 100%|| 1844/1844 [01:42<00:00, 17.97it/s] --- Compressing(test) : 100%|| 32/32 [00:02<00:00, 13.89it/s] --- Calculating mAP : 100%|| 1000/1000 [01:23<00:00, 11.94it/s] 0427 09:37:06 PM EVAL-GreedyHash, bit:48, dataset:cifar10-1, MAP:0.819登录后复制
step4: 训练模型
例如要训练 12bits 的模型,可以运行: In [4]
# 训练模型! python train.py --batch-size 32 --learning_rate 1e-3 --seed 2000 --bit 12# 这里记录是看运行没问题就中断了。登录后复制
W0427 21:38:07.032394 780 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0427 21:38:07.036984 780 device_context.cc:465] device: 0, cuDNN Version: 7.6. Loading AlexNet state from path: /home/aistudio/paddle_greedyhash/models/AlexNet_pretrained.pdparams 0427 09:38:12 PM Namespace(alpha=0.1, batch_size=32, bit=12, crop_size=224, dataset='cifar10-1', epoch=50, epoch_lr_decrease=30, eval_epoch=2, learning_rate=0.001, log_path='logs/', model='GreedyHash', momentum=0.9, n_class=10, num_train=5000, optimizer='SGD', output_dir='checkpoints/', seed=2000, topK=-1, weight_decay=0.0005) 0427 09:38:22 PM GreedyHash[ 1/50][21:38:22] bit:12, lr:0.001000000, dataset:cifar10-1, train loss:1.904 0427 09:38:31 PM GreedyHash[ 2/50][21:38:31] bit:12, lr:0.001000000, dataset:cifar10-1, train loss:1.574 --- Calculating Acc : 100%|| 32/32 [00:02<00:00, 13.48it/s] --- Compressing(train) : 100%|| 1844/1844 [01:46<00:00, 17.28it/s] --- Compressing(test) : 100%|| 32/32 [00:02<00:00, 13.81it/s] --- Calculating mAP : 100%|| 1000/1000 [01:14<00:00, 13.39it/s] 0427 09:41:39 PM save in checkpoints/model_best_12 0427 09:41:40 PM GreedyHash epoch:2, bit:12, dataset:cifar10-1, MAP:0.614, Best MAP: 0.614, Acc: 77.000 0427 09:41:51 PM GreedyHash[ 3/50][21:41:51] bit:12, lr:0.001000000, dataset:cifar10-1, train loss:1.316 0427 09:42:00 PM GreedyHash[ 4/50][21:42:00] bit:12, lr:0.001000000, dataset:cifar10-1, train loss:1.120 --- Calculating Acc : 100%|| 32/32 [00:02<00:00, 13.93it/s] --- Compressing(train) : 46%| | 841/1844 [00:49<00:58, 17.28it/s]^C Traceback (most recent call last): File "train.py", line 183, in <module> main() File "train.py", line 180, in main database_loader) File "train.py", line 136, in train_val mAP, acc = val(model, test_loader, database_loader) File "train.py", line 81, in val retrievalB, retrievalL, queryB, queryL = compress(database_loader, test_loader, model) File "/home/aistudio/paddle_greedyhash/utils/tools.py", line 31, in compress _,_, code = model(data) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py", line 917, in __call__ return self._dygraph_call_func(*inputs, **kwargs) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py", line 907, in _dygraph_call_func outputs = self.forward(*inputs, **kwargs) File "/home/aistudio/paddle_greedyhash/models/greedyhash.py", line 67, in forward x = self.features(x) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py", line 917, in __call__ return self._dygraph_call_func(*inputs, **kwargs) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py", line 907, in _dygraph_call_func outputs = self.forward(*inputs, **kwargs) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/container.py", line 98, in forward input = layer(input) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py", line 917, in __call__ return self._dygraph_call_func(*inputs, **kwargs) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py", line 907, in _dygraph_call_func outputs = self.forward(*inputs, **kwargs) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/conv.py", line 677, in forward use_cudnn=self._use_cudnn) File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/functional/conv.py", line 123, in _conv_nd pre_bias = getattr(_C_ops, op_type)(x, weight, *attrs) KeyboardInterrupt --- Compressing(train) : 46%| | 841/1844 [00:49<00:58, 17.00it/s]登录后复制
step5: 验证预测

验证图片(类别:飞机 airplane, id: 0)
对于上面的图片,直接运行 predict.py 即可,这里拿 bit_48.pdparams 预测一下看看: In [5]
! python predict.py --bit 48 --pic_id 1949登录后复制
W0427 21:43:31.814743 1416 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0427 21:43:31.819936 1416 device_context.cc:465] device: 0, cuDNN Version: 7.6. Loading AlexNet state from path: /home/aistudio/paddle_greedyhash/models/AlexNet_pretrained.pdparams ----- Pretrained: Load model state from output/bit_48.pdparams ----- Predicted Class_ID: 0, Prob: 0.9965014457702637, Real Label_ID: 0 ----- Predicted Class_NAME: 飞机 airplane, Real Class_NAME: 飞机 airplane登录后复制
显然,预测结果正确。
七、代码结构与详细说明
|-- paddle_greedyhash |-- output # 日志及模型文件 |-- bit48_alone # 偶然把bit48跑到了0.824,日志和权重存于此 |-- bit_48.pdparams # bit48_alone的模型权重 |-- log_48.txt # bit48_alone的训练日志 |-- bit_12.pdparams # 12bits的模型权重 |-- bit_24.pdparams # 24bits的模型权重 |-- bit_32.pdparams # 32bits的模型权重 |-- bit_48.pdparams # 48bits的模型权重 |-- log_eval.txt # 用训练好的模型测试日志(包含bit48_alone) |-- log_train.txt # 依次训练 12/24/32/48 bits(不包含bit48_alone) |-- models |-- __init__.py |-- alexnet.py # AlexNet 定义,注意这里有略微有别于 paddle 集成的 AlexNet |-- greedyhash.py # GreedyHash 算法定义 |-- utils |-- datasets.py # dataset, dataloader, transforms |-- lr_scheduler.py # 学习率策略定义 |-- tools.py # mAP, acc计算;随机数种子固定函数 |-- eval.py # 单卡测试代码 |-- predict.py # 预测演示代码 |-- train.py # 单卡训练代码 |-- README.md |-- pytorch_greedyhash |-- datasets.py # PyTorch 定义dataset, dataloader, transforms |-- cal_map.py # PyTorch mAP计算; |-- main.py # PyTorch 单卡训练代码 |-- output # PyTorch 重跑日志登录后复制
八、模型信息
关于模型的详细信息,请参考以下表格:发布者:文洪涛 邮箱:hatimwen@com框架版本:Paddle 应用场景:图像检索 硬件支持:GPU、CPU 下载链接:预训练模型 提取码: tl 在线运行:AI Studio 许可协议:Apache license
九、参考及引用
@article{su2018greedy, title={Greedy hash: Towards fast optimization for accurate hash coding in cnn}, author={Su, Shupeng and Zhang, Chao and Han, Kai and Tian, Yonghong}, year={2018}, journal={Advances in Neural Information Processing Systems}, volume={31}, year={2018}}登录后复制
以上就是【论文复现】基于 PaddlePaddle 实现 GreedyHash的详细内容,更多请关注其它相关文章!
























