基于MobileNetV2的柠檬外观分类实践
更新时间:2026-03-08 13:30:47
-
-
summer爱情故事免费版
- 类型:模拟经营
- 大小:
- 语言:简体中文
- 评分:
- 查看详情
基于MobileNetV2的柠檬外观分类实践
在广岛Quest 檬外观分类赛中,我使用飞桨建了卷积神经网络来解决这个问题。首先解压数据集并用train.csv进行训练,然后将数据集划分成的训练集和的验证集。接着对数据进行了预处理,并创建了一个可视化日志(visualdl)文件,以便更好地监控模型训练过程。最后,我选择了MobileNetV型,并采用了SGD优化器来进行训练,最终在验证集上取得了-的准确率。通过调整参数和架构,可以进一步提高模型性能。

项目的赛题源自比赛广岛Quest2020
柠檬外观分类使用的图像数据(第1阶段)用广岛县的柠檬形象挑战外观分类。
比赛链接https://signate.jp/competitions/431
1.任务描述
在图像分类领域中,对图像的视觉信息进行语义标注是核心目标,同时其又是图像搜索、内容分析及目标识别的关键基础。
本实践旨在通过一个柠檬分类的案列,让大家理解和掌握如何使用飞桨2.0搭建一个卷积神经网络。
特别提示:本实践所用数据集均来自互联网,请勿用于商务用途。
解压文件,使用train.csv进行训练,使用对应的验证集进行测试,并计算验证集上的准确率作为最终得分。
2.调优
通过调整和实践优化模型,使用验证集的准确率作为评估标准,较高的准确率意味着更好的性能!你可以自由替换模型、调整参数并独立实现代码。这样你就可以获得更高的得分了!
解压数据集
In [1]
!cd data $$/ !unzip -oq /home/aistudio/data/data73045/lemon_homework.zip !unzip -oq /home/aistudio/lemon_homework/lemon_lesson.zip -d /home/aistudio/lemon_homework/ !unzip -oq /home/aistudio/lemon_homework/lemon_lesson/test_images.zip -d /home/aistudio/lemon_homework/ !unzip -oq /home/aistudio/lemon_homework/lemon_lesson/train_images.zip -d /home/aistudio/lemon_homework/登录后复制
第一步 观察数据格式 了解赛题目的
题目分析
- 题意 给出了训练集柠檬的图片,让我们输出测试集的图片的规格
- 数据集模样
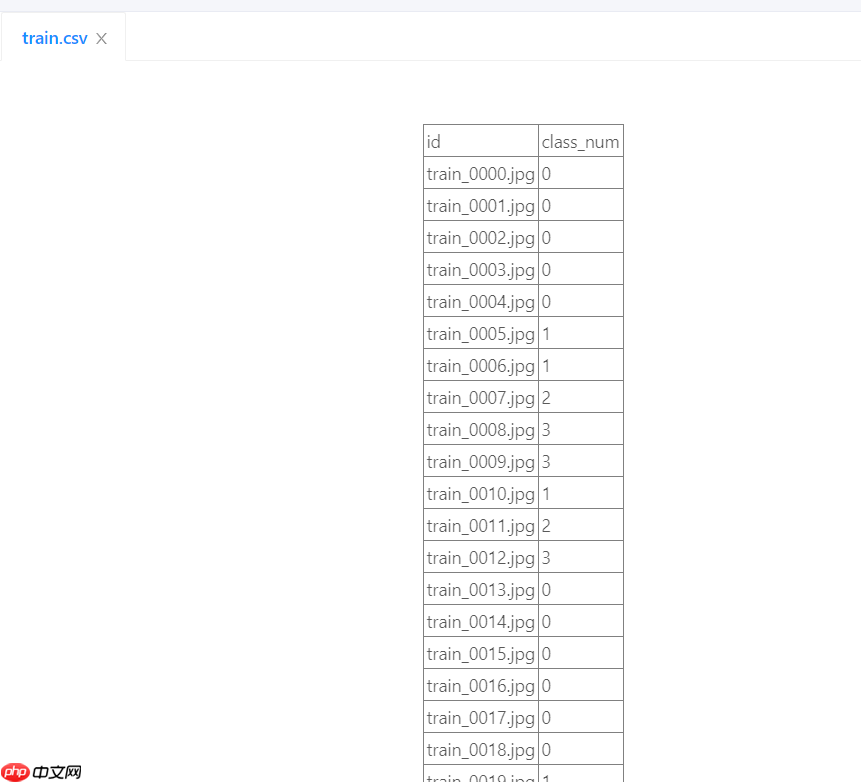
- 关键信息 第一列为id 图片的路径
第二列为label 图片的等级
以下为题目当中给出的:
有四个等级:0:良、1:良、2:加工品、3:格外。

第二步导入必要的库,数据解析并存储
代码逻辑:
导入库->读取数据->打乱数据->划分数据->数据预处理 In [2]
# 导入所需要的库from sklearn.utils import shuffleimport osimport pandas as pdimport numpy as npfrom PIL import Imageimport paddleimport paddle.nn as nnfrom paddle.io import Datasetimport paddle.vision.transforms as Timport paddle.nn.functional as Ffrom paddle.metric import Accuracy #在python中运行代码经常会遇到的情况是代码可以正常运行但是会提示警告,有时特别讨厌。#那么如何来控制警告输出呢?其实很简单,python通过调用warnings模块中定义的warn()函数来发出警告。我们可以通过警告过滤器进行控制是否发出警告消息。import warnings warnings.filterwarnings("ignore")# 读取数据train_images = pd.read_csv('lemon_homework/train.csv', usecols=['id','class_num'])# labelshuffling 自定义标签打乱def labelShuffling(dataFrame, groupByName = 'class_num'): groupDataFrame = dataFrame.groupby(by=[groupByName]) labels = groupDataFrame.size() print("length of label is ", len(labels)) maxNum = max(labels) lst = pd.DataFrame() for i in range(len(labels)): print("Processing label :", i) tmpGroupBy = groupDataFrame.get_group(i) createdShuffleLabels = np.random.permutation(np.array(range(maxNum))) % labels[i] print("Num of the label is : ", labels[i]) lst=lst.append(tmpGroupBy.iloc[createdShuffleLabels], ignore_index=True) print("Done" ) # lst.to_csv('test1.csv', index=False) return lst# 划分训练集和校验集all_size = len(train_images)# print(all_size)train_size = int(all_size * 0.8) train_image_list = train_images[:train_size] val_image_list = train_images[train_size:] df = labelShuffling(train_image_list) df = shuffle(df) train_image_path_list = df['id'].values label_list = df['class_num'].values label_list = paddle.to_tensor(label_list, dtype='int64') train_label_list = paddle.nn.functional.one_hot(label_list, num_classes=4) val_image_path_list = val_image_list['id'].values val_label_list = val_image_list['class_num'].values val_label_list = paddle.to_tensor(val_label_list, dtype='int64') val_label_list = paddle.nn.functional.one_hot(val_label_list, num_classes=4)# 定义数据预处理data_transforms = T.Compose([ T.Resize(size=(224, 224)), T.RandomHorizontalFlip(224), T.RandomVerticalFlip(224), T.RandomRotation(90), T.Transpose(), # HWC -> CHW T.Normalize( mean=[0.31169346, 0.25506335, 0.12432463], #归一化 std=[0.34042713, 0.29819837, 0.1375536], to_rgb=True) #计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]])登录后复制
length of label is 4 Processing label : 0 Num of the label is : 234 Done Processing label : 1 Num of the label is : 156 Done Processing label : 2 Num of the label is : 136 Done Processing label : 3 Num of the label is : 123 Done登录后复制
第三步 构建Dataset
In [3]
# 构建Datasetclass MyDataset(paddle.io.Dataset): """ 步骤一:继承paddle.io.Dataset类 """ def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'): """ 步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集 """ super(MyDataset, self).__init__() self.img = [] self.label = [] # 借助pandas读csv的库 self.train_images = train_img_list self.test_images = val_img_list self.train_label = train_label_list self.test_label = val_label_list if mode == 'train': # 读train_images的数据 for img,la in zip(self.train_images, self.train_label): self.img.append('lemon_homework/train_images/'+img) self.label.append(la) else: # 读test_images的数据 for img,la in zip(self.test_images, self.test_label): self.img.append('lemon_homework/train_images/'+img) self.label.append(la) def load_img(self, image_path): # 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟 image = Image.open(image_path).convert('RGB') return image def __getitem__(self, index): """ 步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签) """ image = self.load_img(self.img[index]) label = self.label[index] # label = paddle.to_tensor(label) return data_transforms(image).astype("float32"), paddle.nn.functional.label_smooth(label) def __len__(self): """ 步骤四:实现__len__方法,返回数据集总数目 """ return len(self.img)#train_loadertrain_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train') train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)#val_loaderval_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test') val_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)登录后复制
第四步 配置visualdl
配置完之后,可以在左侧可视化页面添加日志和模型文件。 In [4]
!rm vdl/vdlrecords.model.logfrom visualdl import LogReader, LogWriter args={ 'logdir':'./vdl', 'file_name':'vdlrecords.model.log', 'iters':0, } write = LogWriter(logdir=args['logdir'], file_name=args['file_name'])#iters 初始化为0iters = args['iters'] #自定义Callbackclass Callbk(paddle.callbacks.Callback): def __init__(self, write, iters=0): self.write = write self.iters = iters def on_train_batch_end(self, step, logs): self.iters += 1 #记录loss self.write.add_scalar(tag="loss",step=self.iters,value=logs['loss'][0]) #记录 accuracy self.write.add_scalar(tag="acc",step=self.iters,value=logs['acc'])登录后复制
rm: cannot remove 'vdl/vdlrecords.model.log': No such file or directory登录后复制
第五步 选择合适的网络并进行模型训练
定义输入->模型封装->定义优化器->配置模型->模型训练与评估 In [5]
from work.mobilenet import MobileNetV2#定义输入input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img") label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64", name="label")# 模型封装model_res = MobileNetV2(class_dim=4) model = paddle.Model(model_res,inputs=input_define,labels=label_define)# 定义优化器scheduler = paddle.optimizer.lr.LinearWarmup( learning_rate=0.1, warmup_steps=20, start_lr=0, end_lr=0.1, verbose=True) optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())# optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())# 配置模型model.prepare( optim, paddle.nn.CrossEntropyLoss(soft_label=True), Accuracy() )# 模型训练与评估model.fit( train_loader, val_loader, epochs=50, callbacks=Callbk(write=write, iters=iters), verbose=1, batch_size=64, save_dir="/home/aistudio/iterhui/" #把模型参数、优化器参数保存至自定义的文件夹 )登录后复制
模型验证
In [6]
#模型保存model.save('Hapi_MyCNN', False) # save for inferenceresult = model.evaluate(val_loader,batch_size=64,log_freq=100, verbose=1, num_workers=0, callbacks=Callbk(write=write, iters=iters))print(result)登录后复制
Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 30/30 [==============================] - loss: 0.4024 - acc: 0.9979 - 642ms/step Eval samples: 936 {'loss': [0.40243444], 'acc': 0.9978632478632479}登录后复制
验证集准确率多次运行大概在98%-100%。
以上就是基于MobileNetV2的柠檬外观分类实践的详细内容,更多请关注其它相关文章!





















