EdgeViTs的一些改进以及完全体复现
更新时间:2026-04-26 13:31:25
-

-
smsforwarder短信转发器 v3.5.0.260224最新版
- 类型:系统工具
- 大小:18.5m
- 语言:简体中文
- 评分:
- 查看详情
EdgeViTs的一些改进以及完全体复现
这篇文章深入探讨了EdgeViTs的研究成果,并详细对比了BN、LN和GN的区别。我们首先将原始的LN层替换为GN层,然后将FFN层简化为两层卷积层,展示了不同计算复杂度下的结构变化。复现还包括了模型的整体组成及实验过程,同时使用Flowers数据集进行训练并可视化效果。

EdgeViTs的一些改进以及完全体复现
1 前言
1.1 EdgeViTs复现回顾
在上一篇文章中,我们详细介绍了EdgeViTs中的关键组件LGL并展示了其在Cifar据集上的实验结果。本次文章则进一步深入了这项技术,实现了EdgeViTs的完整版复现,并在此基础上进行了优化和扩展。
1.2 BN LN GN的区别
在神经网络中,批处理归一化层(Batch Normalization, BN)是不可或缺的一部分。它有四种形态:Batch Normalization (BN)、Layer Normalization (LN)、Instance Normalization (IN)和Group Normalization (GN)。虽然它们的公式看似相似,但实质上各不相同。比如BN通过消除参数依赖,减少了过拟合;而LN则专注于处理高维数据,提供了更灵活的归一化方法。理解这些差异对于优化神经网络性能至关重要。
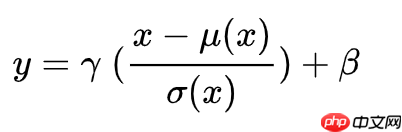
这些归一化算法的关键差异体现在它们处理特征映射维度的方式上。BN受批次大小影响显著,在大批次下表现优异。相比之下,LN、IN和GN在不依赖于批次大小的情况下运行更佳,且GN的效果最为理想。
1.3 Batch Normalization (BN)
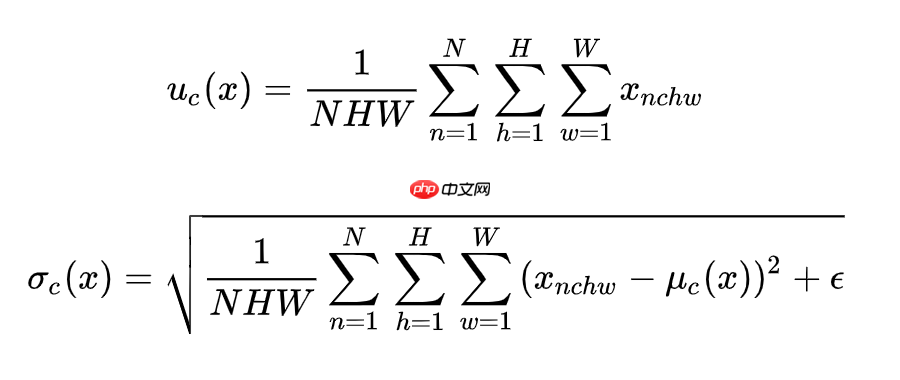
具体而言,是指将第样本的第一个通道的特征图加上第样本的第一通道的特征图直到第N个样本的第一通道的特征图,并求得这N个特征图平均值得到第一个特征图的均值(注意这里要除以N×H×W,而不是简单地除以N,最终得到的是一个代表该批特征图的第一个通道均值的数字,而不仅仅是H×W的一个矩阵)。同样地,对于所有其他通道也按照相同的方法操作。这样处理之后,就能分别获得每个样本的通道平均值和方差。
1.4 Layer Normalization(LN)
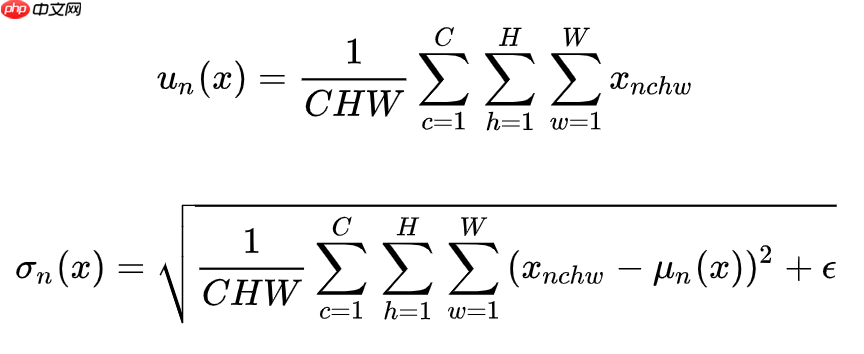
Layer Normalization(LN)的一个显著优势是在不使用批量标准化的情况下,在单个数据点内部对特征进行归一化。LN 通过计算每个样本在 C、H、W 方向上量化的平均值和方差,从而消除局部的统计依赖性,并保持 N 维的独立分布特性。其均值和标准差的公式如下:这个特性使得 LN 在处理具有不同尺度的特征数据时特别有效,从而在保持模型稳定性和泛化能力的同时提高了训练效率。
1.5 Group Normalization (GN)
GN(归一化)计算时,首先将每个样本的特征图通道(feature map's channels)划分为G组,每组含有C/G个通道。接着,分别对每一组的通道元素求均值和标准差。各组通道则根据其对应的归一化参数独立进行归一化处理。这样可以有效地提升模型的表现,并且保持了每个部分的相对重要性。
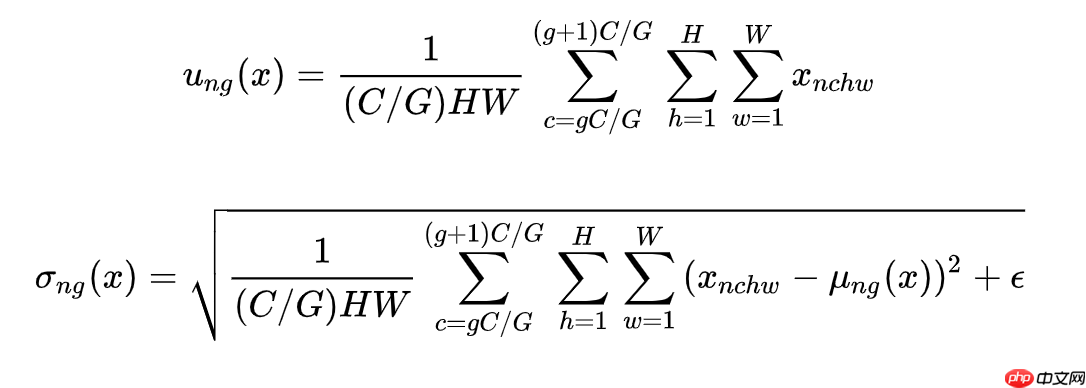
BN LN GN的区别主要参考BN、LN、IN、GN的简介更详细的介绍大家可以点击该链接进行查阅。
2 复现详情
对于大多数依赖于transformer架构的应用来说,归一化层通常采用Leaky Layer Normalization(LN)。然而,在图像处理中,这一概念最初设计用于自然语言处理领域。尽管如此,在transformer框架下将其应用至图像领域时,未进行任何调整。在实际应用场景中,这一效果良好。本项目中的具体操作是:替换原始的Leaky Layer Normalization层为Group Normalization(GN)层,并将全连接层结构从两层改为卷积层形式。这种改动旨在提升模型性能并加快计算速度。
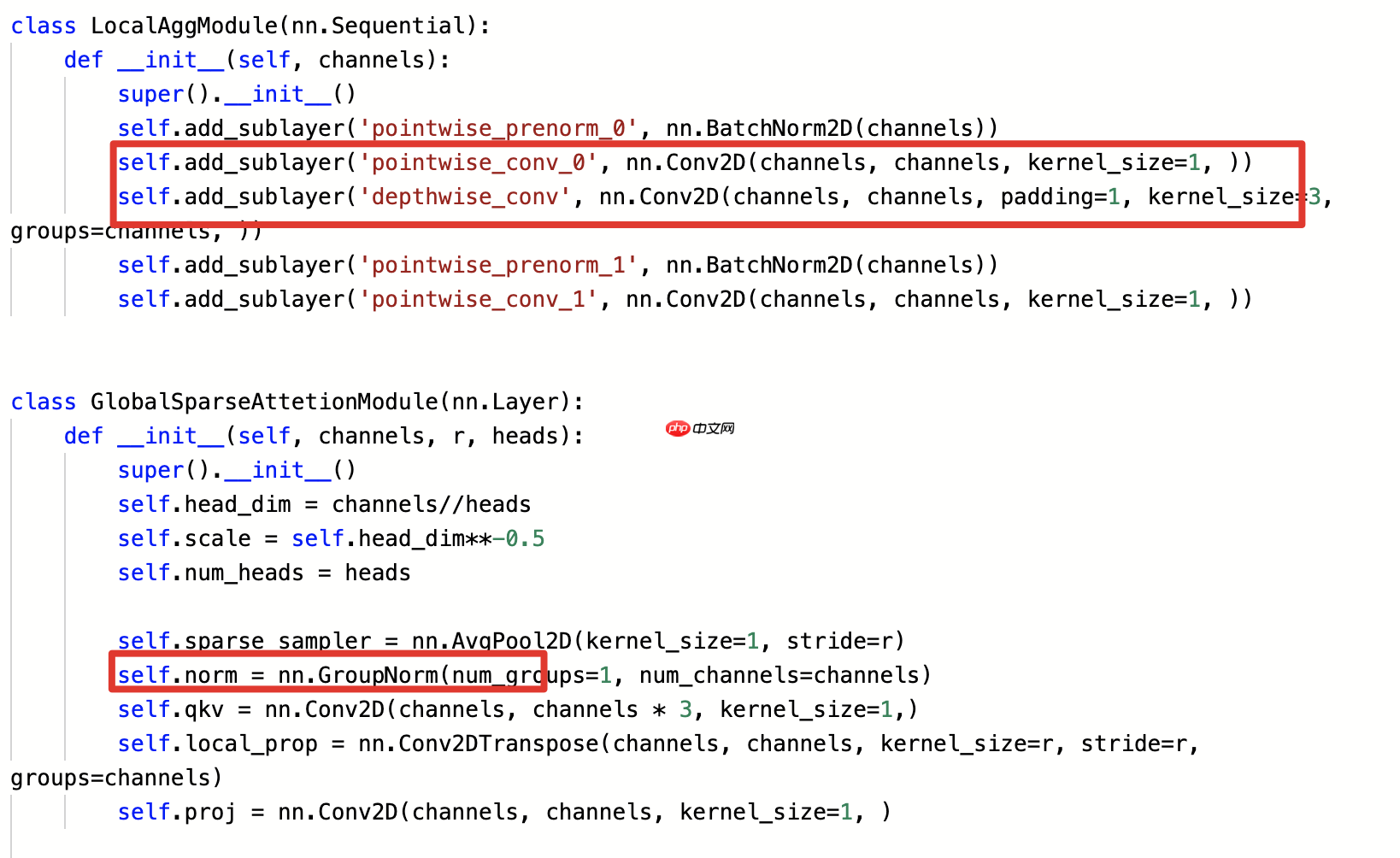
论文作者根据不同计算复杂度构建系列带有LGL瓶颈的EdgeViTs,并总结了几种配置。以下是项目中重现的结构:

EdgeViTs系列结构在之前的分层ViT基础上进行了显著改进。EdgeViTs由四个具有不同空间分辨率的阶段组成,即token序列长度为与之前的模型相比,自注意力模块逐渐减少,并被LGL瓶颈所取代。对于每个阶段,作者使用了一个conv层,核大小为步长为除了第一阶段外,第二阶段采用步长为核进行下采样输入特征。此外,还采用了条件位置编码以优于绝对位置编码的效果。这可以通过深度卷积与残差连接相结合实现。在提出的EdgeViTs模型中,作者使用了具有零填充的度卷积来执行局部聚合操作,在局部聚合及全局稀疏自注意力之前进行。FFN(前馈神经网络)由两个线性层组成,并包含GeLU非线性激活函数。局部聚合操作可以通过point-wise和depth-wise卷积堆叠实现。在全局稀疏注意力方面,EdgeViTs使用了四个阶段的采样率为(的空间均匀采样器和标准MHSA(门控自我注意)。局部传播则通过深度可分离转置卷积来实现,其kernel大小和步长与全局稀疏注意力中使用的相同。总的来说,EdgeViTs利用了更复杂的特征处理方式,提高了模型的性能,并在特定应用场景下表现出色。
3 模型实验
In []
from edgevit import EdgeViT_XXS, EdgeViT_XS, EdgeViT_Simport paddle model = EdgeViT_XXS() paddle.summary(model,(1,3,224,224))登录后复制 In []
import paddlefrom paddle.metric import Accuracyfrom paddle.vision.datasets import Flowersfrom paddle.vision.transforms import Compose, Normalize, Resize, Transpose, ToTensor callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir') normalize = Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], data_format='HWC') transform = Compose([ToTensor(), Normalize(), Resize(size=(224,224))]) cifar10_train = paddle.vision.datasets.Flowers(mode='train', transform=transform) cifar10_test = paddle.vision.datasets.Flowers(mode='test', transform=transform)# 构建训练集数据加载器train_loader = paddle.io.DataLoader(cifar10_train, batch_size=128, shuffle=True)# 构建测试集数据加载器test_loader = paddle.io.DataLoader(cifar10_test, batch_size=128, shuffle=True) model = paddle.Model(EdgeViT_XXS()) optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()) model.prepare( optim, paddle.nn.CrossEntropyLoss(), Accuracy() ) model.fit(train_data=train_loader, eval_data=test_loader, epochs=20, callbacks=callback, verbose=1 )登录后复制
3.1 可视化训练过程
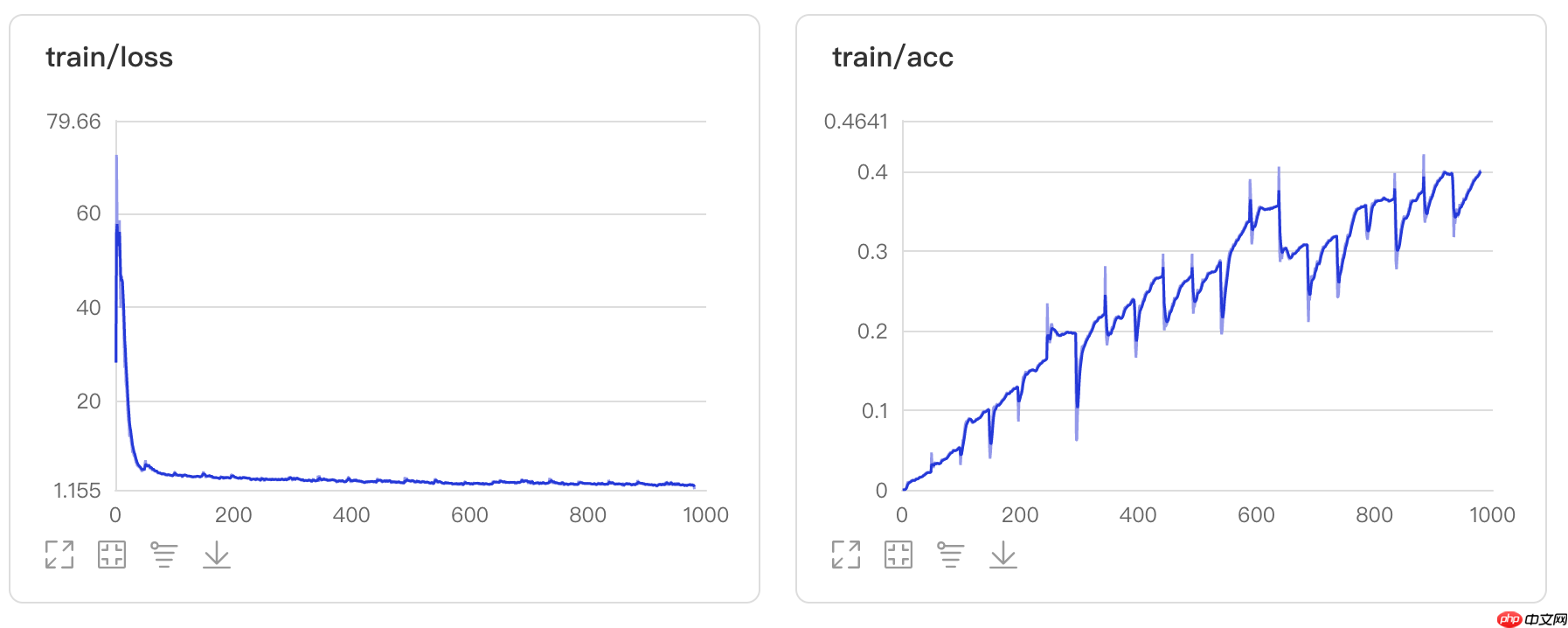
以上就是EdgeViTs的一些改进以及完全体复现的详细内容,更多请关注其它相关文章!























