基于Seq2Seq的聊天机器人
时间:2025-12-26
-

-
phigros最新版
- 类型:棋牌桌游
- 大小:1.85gb
- 语言:简体中文
- 评分:
- 查看详情
基于Seq2Seq的聊天机器人
本文围绕基于Seq2Seq的聊天机器人展开,先介绍Seq2Seq在机器翻译、文本生成、情感分析等方面的应用,阐述其编码器-解码器的网络结构及理论基础。接着讲解实操过程,包括安装依赖、数据预处理(分词、构建字典等)、搭建Encoder和Decoder结构并组网,还涉及模型训练、测试函数构建等内容,最后说明因数据集少效果有限但能进行基础对话。

基于Seq2Seq的聊天机器人
将一个句子转换为另一个句子序列到序列模型(Seqeq)的应用:- 机器翻译:提供源语言的文本自动转换为目标语言,保持原始文本结构;- 文本生成:包括客户服务对话和情感分析。例如,从正面或负面情绪判断文本的情感倾向。
Seq2Seq 理论
概述
聊天机器人的研究可以追溯到20世纪50年代。Alan Turing提出了一个图灵测试来回答“机器会思考吗?”这一问题,然后掀起了人工智能研究的热潮。 然而,近年来,大型语言建模技术发展迅速。但是,我们仍然需要学习传统的nlp技术,如果我们想在未来走得更远,我们必须有深厚的基础。一种常见的端到端序列学习方法seq2seq使用多层长短期记忆(LSTM)将输入序列映射到固定维向量,然后使用另一种深度LSTM从向量解码到目标序列。
网络结构解释
参考沐神的讲解哈,用机器翻译的例子
Seqeq(序列到序列),又称作生成方法,是一种通过特定途径从给定序列生成另一个序列的方法,并且两个序列的长度可以不一致。此结构也被称为编码器-解码器模型,即编码-解码模型,是RNN的一种变体,用于解决RNN需等长序列的问题。
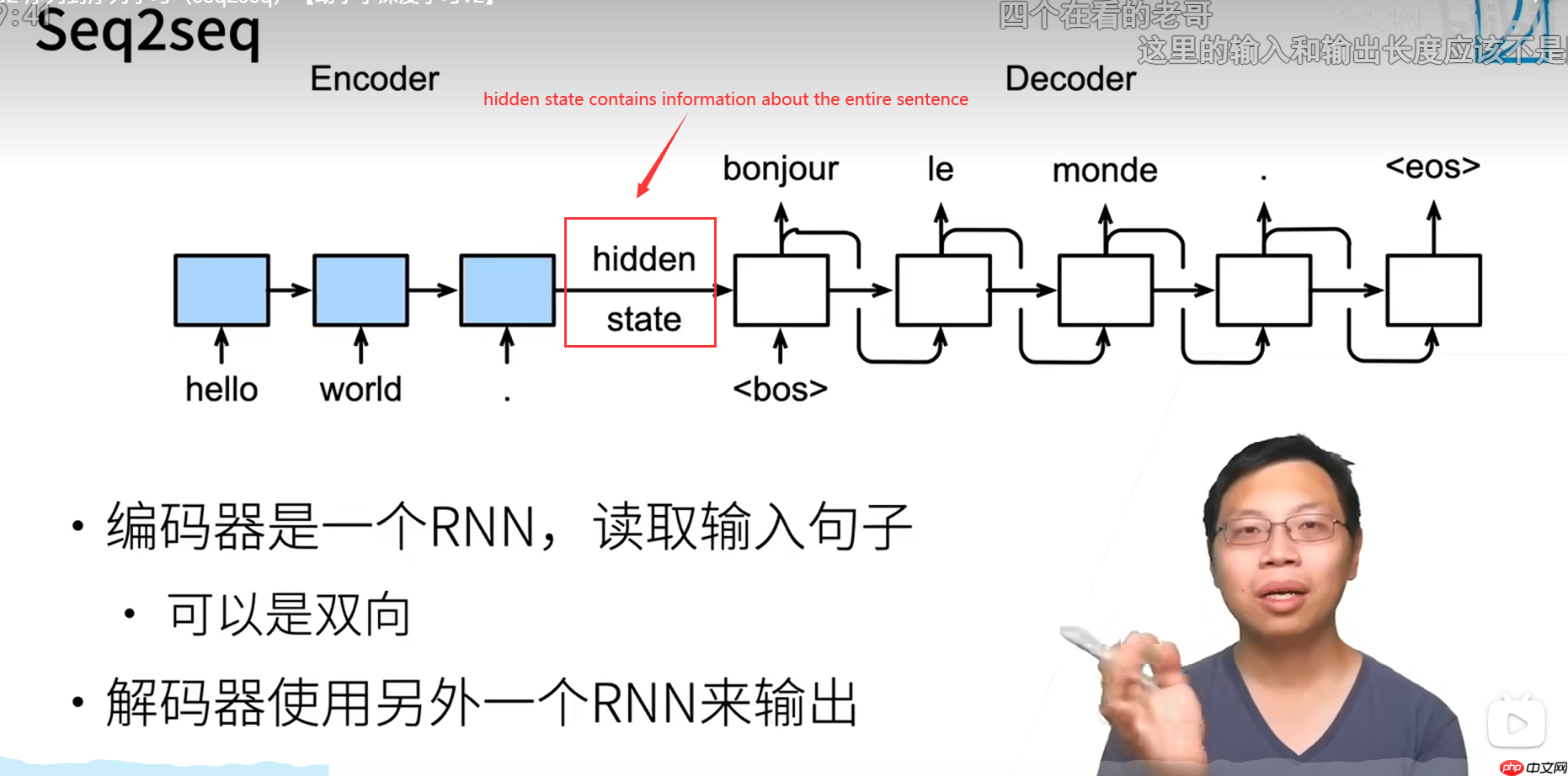
Encoder
通过双向递归神经网络(Bi-Directional Recurrent Neural Networks, Bi-RNN),RNN可以接受输入的正向和反向传递。编码器将长度可变的序列转换为形状固定的上下文变量,并在此过程中利用输入序列的信息进行编码。这样,我们可以从多个角度理解和处理文本信息。
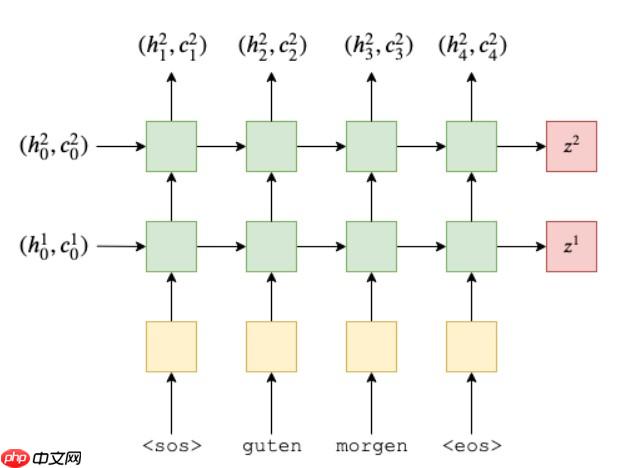
在前向计算中,我们将源语句传入并使用嵌入层将其转换为密集向量,接着应用dropout。最后,我们把这些矢量传递到RNN网络中。当将整个序列传递给RNN时,它会自动处理整个序列的隐藏状态递归计算过程。值得注意的是,我们没有将初始的隐藏状态或单元状态传递给RNN,这是因为如果没有这部分信息,Paddle将自动创建一个全零张量作为初始状态。以下是代码示例:```python # 前向计算 def forward(x): # 将源语句转换为密集向量 embedded = embedding_layer.forward(x) # 应用dropout层 drop_out = dropout_layer.forward(embedded) # 将矢量传递给RNN网络 outputs, hidden_states = rnn_network(drop_out) ```这个过程展示了如何将输入序列转换为密集向量并自动处理隐藏状态,同时避免了手动初始化和计算的过程。
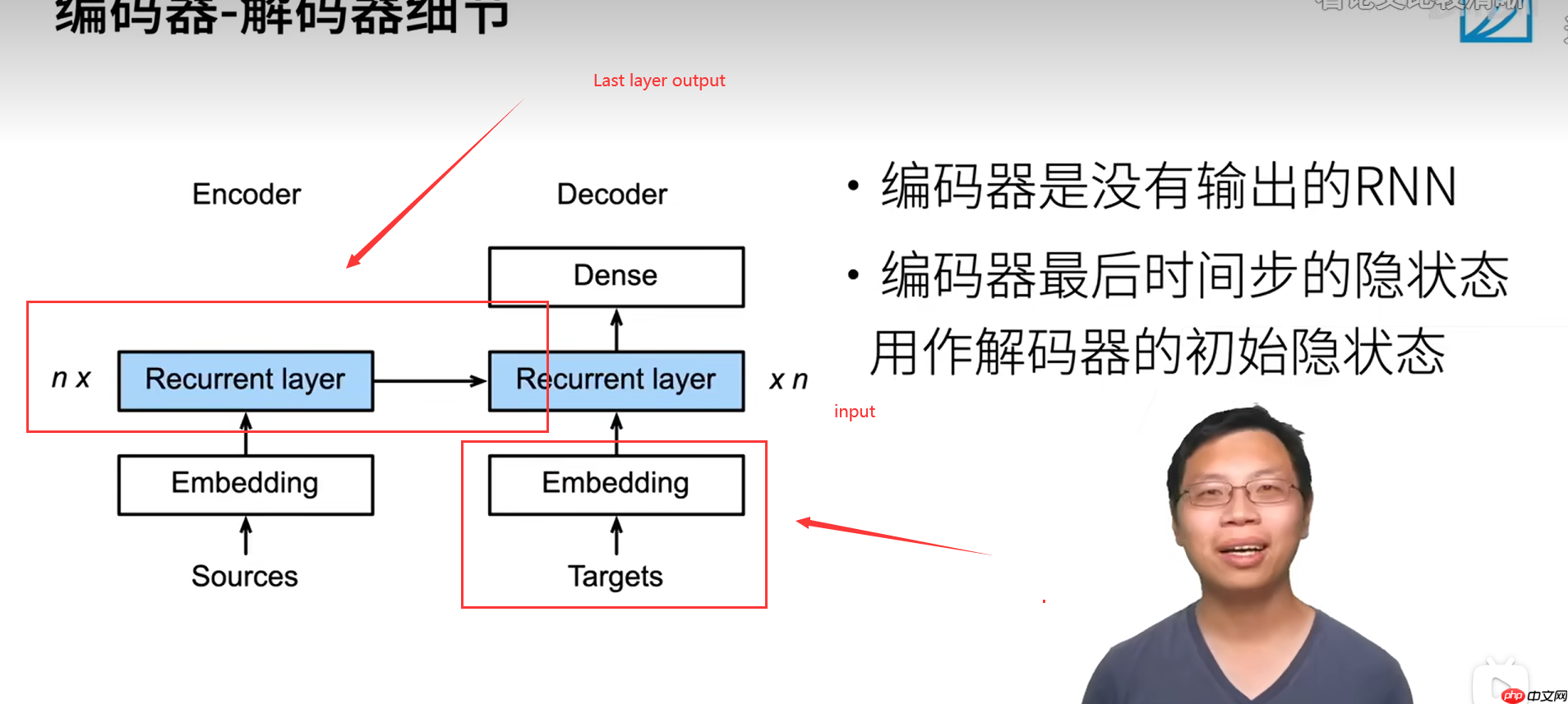
这是一个编码器的实现,使用了嵌入层和LSTM作为主要组成部分。在输入x上应用了一个dropout层以防止过拟合,并通过自定义方法`forward`处理数据流。最终输出包含隐藏状态(h)和单元状态(c),它们是处理序列信息的关键组件。
Decoder
The function is to output text(输出文本)
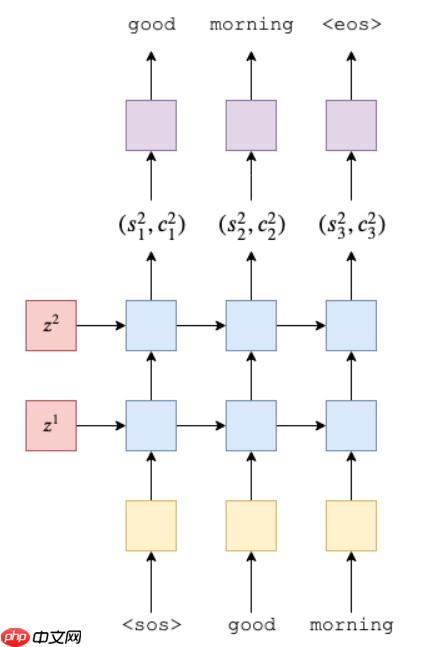
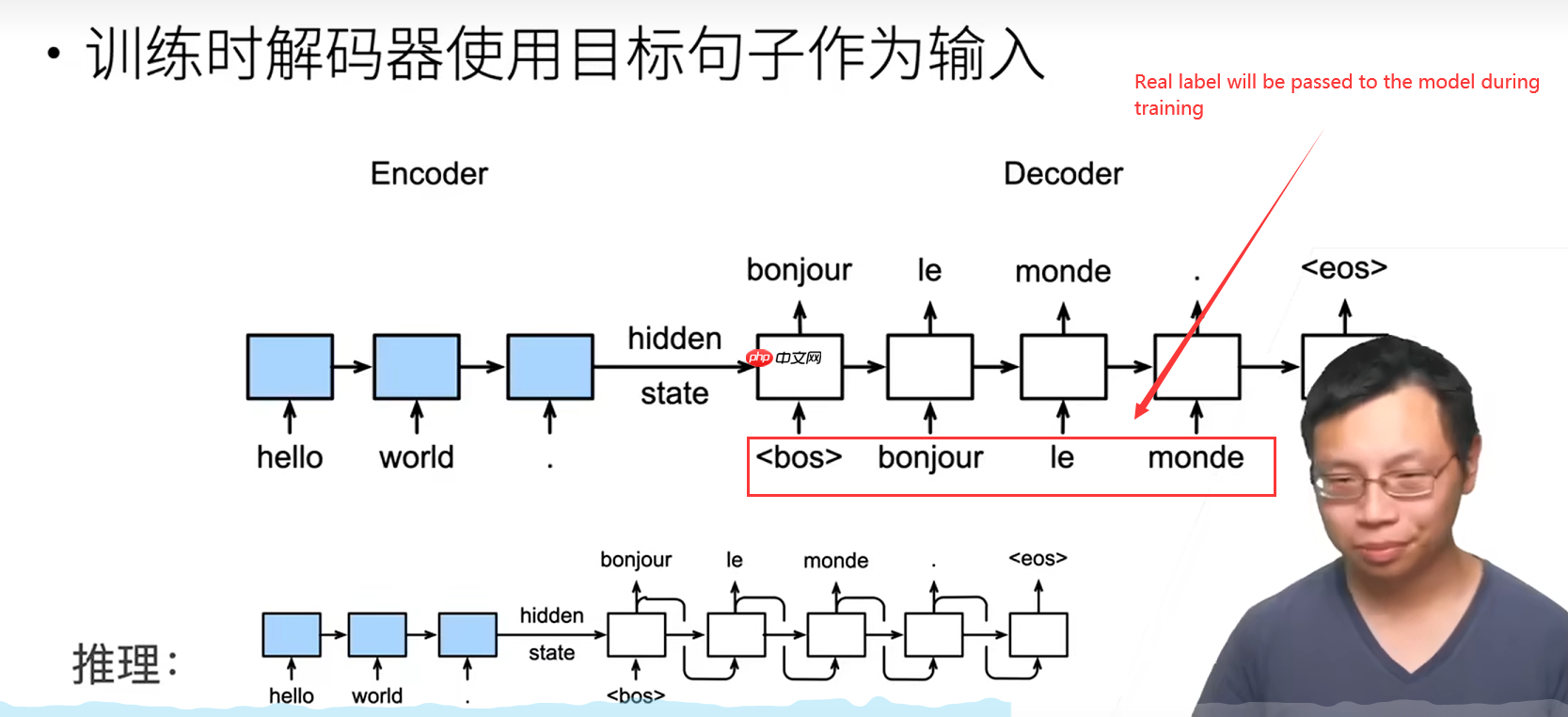
理论就到这里了哈~ 接下来我将以一个简单的例子,快速实现一个基于s2s的聊天机器人
实操聊天机器人
安装依赖 In [1]
!pip install jieba !pip install --upgrade pip登录后复制
Looking in indexes: https://mirror.baidu.com/pypi/simple/, https://mirrors.aliyun.com/pypi/simple/ Requirement already satisfied: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (0.42.1)[notice] A new release of pip available: 22.1.2 -> 24.0[notice] To update, run: pip install --upgrade pipLooking in indexes: https://mirror.baidu.com/pypi/simple/, https://mirrors.aliyun.com/pypi/simple/ Requirement already satisfied: pip in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (22.1.2) Collecting pip Downloading https://mirrors.aliyun.com/pypi/packages/8a/6a/19e9fe04fca059ccf770861c7d5721ab4c2aebc539889e97c7977528a53b/pip-24.0-py3-none-any.whl (2.1 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 MB 316.0 kB/s eta 0:00:0000:0100:01 Installing collected packages: pip Attempting uninstall: pip Found existing installation: pip 22.1.2 Uninstalling pip-22.1.2: Successfully uninstalled pip-22.1.2 Successfully installed pip-24.0登录后复制
数据预处理
使用的数据是对话构成的如下图所示:
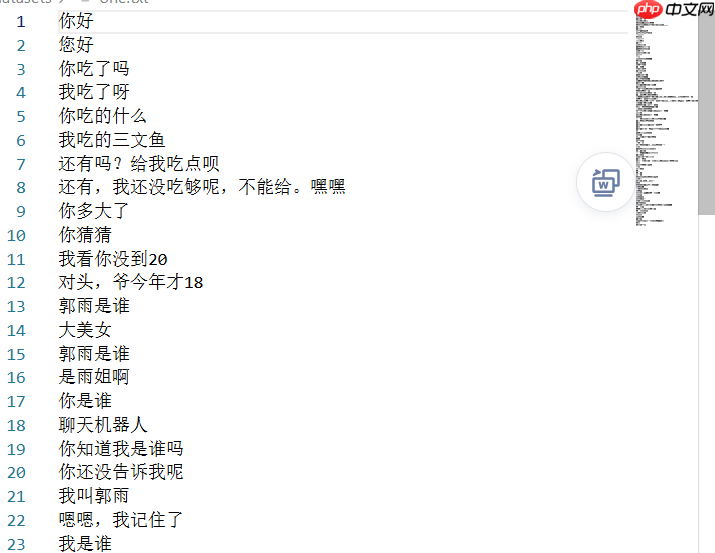
首先,我们要对原始数据进行初步处理,移除无效字符后,再将每个句子拆分成词语,接着将这些词语转换为向量形式。这一步骤是构建自然语言处理模型的基础步骤之一。
import jiebaimport numpy as npimport re#将无效字符去掉with open("datasets/one.txt","r",encoding="utf-8") as f:# with open("data/data86810/human_chat.txt","r",encoding="utf-8") as f: data=f.read().replace("Human 1"," ").replace("Human 2"," ").replace("."," ").replace("*"," ").replace("@"," ").replace("^"," ").replace("&"," ").replace("!"," ").replace("#"," ").replace("$"," ").replace("?"," ").replace(";"," ").replace(":"," ").replace(","," ").replace('"',' ').replace("%"," ").replace("/"," ").replace("@"," ").replace("("," ").replace(")"," ").replace("'"," ").lower() data=list(data.split("\n"))#print(len(data))lst=[]#分割出单词,连成序列for obj in data: # sen=list(obj.split(" ")) sen=list(jieba.cut(obj, cut_all=False)) lst.append(sen)登录后复制
Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache Loading model cost 1.100 seconds. Prefix dict has been built successfully.登录后复制 In [2]
# 分词结果lst登录后复制
[['你好'], ['您好'], ['你', '吃', '了', '吗'], ['我', '吃', '了', '呀'], ['你', '吃', '的', '什么'], ['我', '吃', '的', '三文鱼'], ['还有', '吗', '?', '给', '我', '吃', '点', '呗'], ['还有', ',', '我', '还', '没吃够', '呢', ',', '不能', '给', '。', '嘿嘿'], ['你', '多', '大', '了'], ['你', '猜猜'], ['我', '看', '你', '没到', '20'], ['对头', ',', '爷', '今年', '才', '18'], ['郭雨', '是', '谁'], ['大美女'], ['郭雨', '是', '谁'], ['是', '雨姐', '啊'], ['你', '是', '谁'], ['聊天', '机器人'], ['你', '知道', '我', '是', '谁', '吗'], ['你', '还', '没', '告诉', '我', '呢'], ['我', '叫', '郭雨'], ['嗯', '嗯', ',', '我', '记住', '了'], ['我', '是', '谁'], ['郭雨'], ['今天天气', '怎么样', '?'], ['很', '好', '。'], ['你', '感冒', '了', '?'], ['有点', '难受', '。'], ['你', '几岁', '?'], ['年龄', '是', '秘密'], ['你', '是', '哪里', '人'], ['中国', '人'], ['你', '家里', '有', '谁', '?'], ['我', '家里', '有', '你', '呀'], ['你', '是', '男', '的', '女', '的', '?'], ['我', '?', '可', '男', '可女', '可上', '可下', '可攻', '可受'], ['你', '哪位', '?'], ['额', ',', '你', '查户口', '的', '是', '吗', '?'], ['你好', ',', '在', '吗'], ['在', '的', '噢', ',', '请问', '有', '啥', '能', '帮', '你', '的', '么'], ['这件', '衣服', '有货', '吗'], ['请稍等', ',', '我', '帮', '您', '查', '一下'], ['你们', '的', '衣服', '质量', '怎么样', '啊'], ['质量', '您', '绝对', '可以', '放心', ',', '如果', '有', '任何', '质量', '问题', '我们', ',', '7', '天', '之内', '包', '退换'], ['衣服', '穿着', '不合身', ',', '怎么办'], ['亲', ',', '如果', '衣服', '实在', '穿着', '不合身', '的话', '我们', '是', '可以', '为', '您', '提供', '退换', '服务', '的', ',', '您', '先', '了解', '一下', '我们', '的', '退换货', '须知', '噢'], ['昨晚', '你', '睡', '得', '好', '吗', '?'], ['不', '知道', ',', '因为', '我', '睡着', '了', '。'], ['水果', '什么', '时候', '采摘', '最好', '?'], ['主人', '不', '在', '的', '时候', '。'], ['防止', '食物', '坏掉', '的', '最好', '的', '方法', '是', '什么', '?'], ['吃掉', '。'], ['不能', '冷冻', '的', '液体', '是', '什么', '?'], ['热水', '。'], ['为什么', '自由', '女神像', '站', '在', '纽约', '港口', '?'], ['因为', '她', '不能', '坐下', '来', '。'], ['你好'], ['你好', '呀', ',', '希望', '你', '今天', '过', '的', '快乐'], ['你好'], ['你好', '呀', ',', '~', '有', '什么', '新鲜事儿', '要', '对我讲', '?'], ['早'], ['但', '现在', '是', '上午', '呢', '。'], ['我爱你'], ['我', '也', '爱', '你', ',', '被', '你', '发现', '了'], ['谢谢'], ['不', '客气', '。'], ['再来一个'], ['目前', '还', '不会', '呀', ',', '和', '我', '聊点', '别的', '吧', ' '], ['小明'], ['你', '认识', '他', '啊', ',', '好', '厉害', '啊'], ['不', '和', '你', '玩', '了'], ['为什么', '你', '不', '跟', '我', '玩儿', '[', '哼', ']'], ['你', '是', '人', '吗'], ['我', '不是', '人', '难道', '是', '鬼', '啊'], ['你', '是', '什么', '人'], ['不是', '一般', '人', ',', '但', '一般', '人', '都', '喜欢', '我', '!', '奏', '是', '这么', '牛', '!'], ['傻', '逼'], ['我', '痛苦', '地', '捂住', '了', '脸'], ['老虎'], ['兽中之王'], ['欢迎'], ['欢迎', '你'], ['吓', '着', '了'], ['没有', ',', '妹纸', '怎么', '会', '吓', '到', '人'], ['潜水', '中'], ['别潜', '了', ' ', '起来', '和', '我', '玩吧'], ['哈哈'], ['哈哈', '。', '那', '你', '今年', '多大', '了', '呀', ' '], ['他帅', '吗', '?'], ['再帅', '有', '我帅', '吗'], ['他', '很丑'], ['啊', ',', '有', '多丑', '?', '凤姐', '一般', '吗', '?'], ['非常', '丑'], ['我', '不', '丑', '吗'], ['我', '说', '的', '对', '吧'], ['说', '的', '实在', '太对', '了'], ['你', '说', '的', '不', '对'], ['聪明', '的', '小', '主人', ',', '那', '你', '说', '怎么', '才', '是', '对', '的', '呀', '?'], ['杨惠', '好丑'], ['谢谢', '小', '主人', ',', '我', '记住', '了'], ['杨惠', ',', '我', '渣', '吗'], ['好', '', '啊', '好', ''], ['说话', '啊'], ['聊天', '吗', '?'], ['你好', '丑'], ['我', '丑', '喔', '自信', '好', '吧', ',', '别闪', '瞎', '你', '的', '眼'], ['大神'], ['大神', '不敢当']]登录后复制 In [3]
这是一个将字符连接起来制作字典并处理字符串的过程:首先使用列表推导式将字符列表中的元素以空格进行分隔;接着将特殊字符添加到原字符串中,形成新的字符串用于后续处理。通过正则分割方法去除可能的多余空白,并通过集合确保词项不重复出现。最后计算单词数量和构建字典,完成上述操作后打印出字典长度,即为最终结果。
- 录后复制
由于数据集稀缺,在使用jieba进行分词后,我们构建了一个字典。其中,字典的键代表字符,而值则指向向量的位置,这些元素共同构成了一句话的向量表示。
dic登录后复制
sen_len 也可以理解为每个向量的维度 In [5]
#存储对话序列index_data=[]#每句话的长度,短句添加"pad",长句切至en_len=or i,sen in enumerate(lst): #token映射至index,并防止出现空字符 sen=[dic[word] for word in sen if word!='' and word!=' '] #在开头添加"sos" sen.insert(dic["sos"]) while len(sen)<sen_len- #填充"pad",防止长度不够 sen.append(dic["pad"]) #切取sen_len-词 sen=sen[:sen_len- #末尾添加"eos" sen.append(dic["eos"]) #将ask与answer分割 if i%= one=[] one.append(sen) else: one.append(sen) index_data.append(one)#print(len(index_data))index_data=np.array(index_data)print(index_data.shape)print(index_data[)
(54, 2, 10) [[ 10 205 219 219 219 219 219 219 219 131] [ 10 13 219 219 219 219 219 219 219 131]]登录后复制
在进行处理时,我们将每个句子转换成了一个向量,用于后续推理。这种做法使得我们可以利用Ensembling技术来提升预测的准确性,并简化演示过程中的复杂度。例如,我们可以使用现有的神经网络模型(如Ensembled Model)来进行处理,但为了简单起见,在这个示例中并未使用这一方法。
#挑一个看看效果ask,ans=index_data[3]#将index序列转化为字符串ask_str=[words[i] for i in ask] ans_str=[words[i] for i in ans]print(ask_str)print(ans_str)#print(dic)登录后复制
['sos', '还有', '吗', '?', '给', '我', '吃', '点', '呗', 'eos'] ['sos', '还有', ',', '我', '还', '没吃够', '呢', ',', '不能', 'eos']登录后复制
DataLoader
在训练时高效加载数据至关重要,需创建DataLoader将数据存入内存或显存,确保加速处理。
import paddlefrom paddle.io import Dataset,DataLoaderimport paddle.nn as nnimport random#batch大小batch_size=128class Mydataset(Dataset): def __init__(self,index_data,dic): super(Mydataset, self).__init__() self.index_data=index_data self.dic=dic def __getitem__(self,index): ask_data,ans_data=self.index_data[index] #ask部分倒序,引入更多短期依赖关系 ask_data,ans_data=ask_data[:][::-1],ans_data return ask_data,ans_data def __len__(self): return self.index_data.shape[0]#实例化读取器dataset=Mydataset(index_data,dic)#封装为迭代器dataloader=DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)#看看效果for _,__ in dataloader(): print(_,__) # break登录后复制
数据加载器构建成功之后,我们就要开始搭建网络了。
构建Encoder结构
在encoder中使用了paddle的高级API nn.Lstm网络结构 In [9]
class Encoder(nn.Layer): def __init__(self,vocab_size,emb_dim,hid_dim,drop_out,n_layers): super(Encoder, self).__init__ self.hid_dim = hid_dim self.n_layers = n_layers self.emb = nn.Embedding(vocab_size, emb_dim) #[batch_size,sen_len,emb_dim] self.lstm = nn.LSTM(emb_dim,hid_dim,n_layers) self.drop = nn.Dropout(drop_out) def forward(self,x): x = self.drop(self.emb(x)) # x:[batch_size,sen_len,emb_dim] y,(h,c) = self.lstm(x) # y:[batch size,sen_len,hid dim*n_directions] return h, cvocab_size=len(dic) emb_dim= hid_dim= drop_out=7 n_layers=实例化encoder encoder = Encoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers)x=paddle.randint([batch_size,sen_len]) h,c=encoder(x)#看看形状 print(h.shape,c.shape)
[2, 128, 256] [2, 128, 256]登录后复制
搭建Encoder结构
In [10]
class Decoder(nn.Layer): def __init__(self,vocab_size,emb_dim,hid_dim,drop_out,n_layers): super(Decoder, self).__init__() self.vocab_size=vocab_size self.emb_dim=emb_dim self.hid_dim=hid_dim self.emb=nn.Embedding(vocab_size,emb_dim) self.lstm=nn.LSTM(emb_dim,hid_dim,n_layers) self.drop=nn.Dropout(drop_out) self.fc=nn.Linear(hid_dim,vocab_size) def forward(self,x,hidden,cell): #x = [batch_size] #hidden = [n_layers*n_directions, batch_size, hid_dim] #cell = [n_layers*n_directions, batch_size, hid_dim] #扩维 x=paddle.unsqueeze(x,axis=1) #x=[batch_size,1] x=self.drop(self.emb(x)) #x=[batch_size,emb_dim] output,(h,c)=self.lstm(x,(hidden,cell)) #output = [batch_size,1, hid_dim * n_directions] #hidden = [n_layers * n_directions, batch_size, hid_dim] #cell = [n_layers * n_directions, batch_size, hid_dim] prediction=self.fc(output.squeeze(1)) #prediction=[batch_size,vocab_size] return prediction,h,c decoder=Decoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers) x=paddle.randint(0,136,[batch_size]) y,h,c=decoder(x,h,c)print(y.shape)登录后复制
[128, 241]登录后复制
Encoder 和 Decoder 组网
In [11]
import randomclass seq2seq(nn.Layer): def __init__(self,encoder,decoder): super(seq2seq, self).__init__() nn.initializer.set_global_initializer(nn.initializer.XavierNormal(),nn.initializer.Constant(0.)) self.encoder=encoder self.decoder=decoder def forward(self,source,target,teacher_forcing_ratio=0.5): #src = [batch_size,src_len] #trg = [batch_size,trg_len] #teacher_forcing_ratio is probability to use teacher forcing target_len=target.shape[1] batch_size=target.shape[0] outputs=paddle.zeros([target_len,batch_size,decoder.vocab_size]) #outputs=[tar_len,batch_size,vocab_size] hidden,cell=self.encoder(source) #x为第一个词"sos" x=target[:,0] #loop (tar_len-1)次 for t in range(1,target_len): output,hidden,cell=self.decoder(x,hidden,cell) #保存token的张量 outputs[t]=output #判断是否动用teacher_forcing flag=random.random()<teacher_forcing_ratio #目标token top1=paddle.argmax(output,axis=1) #x为下一个输入token x=target[:,t] if flag else top1 return outputs x=paddle.randint(0,136,[20,sen_len]) y=paddle.randint(0,136,[20,sen_len]) model=seq2seq(encoder,decoder) predict=model(x,y)print(predict.shape)登录后复制
[10, 20, 241]登录后复制
查看网络结构
In [12]
#截断梯度@paddle.no_grad()def init_weights(m): for name, param in m.named_parameters(): #均匀分布初始化 param.data=paddle.uniform(min=-0.2,max=0.2,shape=param.shape)#模型初始化model.apply(init_weights)登录后复制
seq2seq( (encoder): Encoder( (emb): Embedding(241, 128, sparse=False) (lstm): LSTM(128, 256, num_layers=2 (0): RNN( (cell): LSTMCell(128, 256) ) (1): RNN( (cell): LSTMCell(256, 256) ) ) (drop): Dropout(p=0.7, axis=None, mode=upscale_in_train) ) (decoder): Decoder( (emb): Embedding(241, 128, sparse=False) (lstm): LSTM(128, 256, num_layers=2 (0): RNN( (cell): LSTMCell(128, 256) ) (1): RNN( (cell): LSTMCell(256, 256) ) ) (drop): Dropout(p=0.7, axis=None, mode=upscale_in_train) (fc): Linear(in_features=256, out_features=241, dtype=float32) ) )登录后复制 In [13]
def check(str_lst): index_set=set(str_lst) #筛掉重复的单词 lst=list(index_set) #重复次数 zeros=[0 for index in lst] #组合为字典 index_dic=dict(zip(lst,zeros)) index_list=[] #找出重复的index地方 for i in range(len(str_lst)): index=str_lst[i] if index in index_set: index_dic[index]+=1 if index_dic[index]>1: index_list.append(i) #删除重复处 str_lst=np.delete(str_lst,index_list) str_lst=paddle.to_tensor(str_lst,dtype="int64") return str_lst arr=np.array([1,2,3,4,1,1,2,2])print(check(arr))登录后复制
Tensor(shape=[4], dtype=int64, place=CPUPlace, stop_gradient=True, [1, 2, 3, 4])登录后复制
为了方便测试,构建个函数
In [14]
``` # 测试函数 def evaluate(model, ask_sen=ask): ask_sen = paddle.to_tensor(ask_sen).unsqueeze(axis= tar = paddle.zeros([ len(sen_len)]) # 第一个token设为sos tar[ = dic[sos] tar = tar.astype(int) ans = model(ask_sen, tar, # 压扁batch_size层 ans = ans.squeeze(axis= ans = ans.argmax(axis= ans_str = [words[i] for i in ans] string = & .join(ans_str) return stringprint(evaluate(model, ask)) ```
冷冻 没到 猜猜 他帅登录后复制
模型训练
现在我们有了数据,有了网络结构,就可以开始训练了哈~ In [15]
learning_rate=2e-4epoch_num=1000#梯度裁剪,防止LSTM梯度爆炸clip_grad=nn.ClipGradByNorm(1)#设定loss,并忽略"pad"这个tokenloss=nn.CrossEntropyLoss(ignore_index=dic["pad"])#实例化优化器optimize=paddle.optimizer.Momentum(learning_rate,parameters=model.parameters(),grad_clip=clip_grad) model.train()for epoch in range(epoch_num): for i,(user_data,assist_data) in enumerate(dataloader()): #清除梯度 optimize.clear_grad() #获取预测张量 predict=model(user_data,assist_data,0) #将predict展开,并去掉第一个词 predict=paddle.reshape(predict[1:],[-1,vocab_size]) #将assist_data展开,并去掉第一个词 assist_data=paddle.reshape(assist_data[:,1:],[-1]) #原predict=[0,y_hat1,y_hat2...] #原assist_data=["sos",y1,y2...] #因此要将第一个词去掉 predict=paddle.to_tensor(predict,dtype="float32") str_predict=predict.argmax(axis=1) str_del=check(str_predict.numpy()) #print("predict:",str_predict) #print("del:",str_del) num=str_predict.shape[0]-str_del.shape[0] assist_data=paddle.to_tensor(assist_data,dtype="int64") #获取损失值 avg_loss=loss(predict,assist_data) #print(avg_loss.numpy(),num) avg_loss+=num #反向传播求梯度 avg_loss.backward() #优化参数 optimize.minimize(avg_loss) #清除梯度 optimize.clear_grad() if i%10==0: print("epoch:%d,i:%d,loss:%f"%(epoch,i,avg_loss.numpy())) print(evaluate(model,index_data[random.randint(0,500)][0])) if epoch%10==0: #保存模型参数 paddle.save(model.state_dict(),"work/zh/seq2seq_1.pdparams")登录后复制
开始测试
由于数据集不足,模型训练速度较快但效果一般。然而,基本对话功能仍可信赖。加载已完成的模型。
encoder=Encoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers) decoder=Decoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers) model=seq2seq(encoder,decoder) state_dict=paddle.load("work/zh/seq2seq.pdparams") model.load_dict(state_dict)登录后复制
接下来构建一个将向量转为句子的函数 In [16]
def transform(index_tensor): string=[words[i] for i in index_tensor] return " ".join(string)登录后复制
测试开始
In [20]
print("human 1:",transform(index_data[10][0]))print("human 2",evaluate(model,index_data[10][1]))登录后复制
human 1: sos 我 叫 郭雨 pad pad pad pad pad eos human 2 冷冻 没到 猜猜登录后复制 In [22]
transform(index_data[10][0])登录后复制
'sos 我 叫 郭雨 pad pad pad pad pad eos'登录后复制
以上就是基于Seq2Seq的聊天机器人的详细内容,更多请关注其它相关文章!













